
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 딥러닝
- FineGrained
- Vision
- 머신러닝
- PRML
- computervision
- ML
- REACT
- clean code
- algorithm
- nerf
- CV
- nlp
- SSL
- Torch
- Front
- Depth estimation
- 알고리즘
- web
- 3d
- Python
- GAN
- classification
- FGVC
- math
- pytorch
- dl
- 자료구조
- Meta Learning
- cs
- Today
- Total
KalelPark's LAB
[ 논문 리뷰 ] MobileViT : Light-Weight, General-purpose, and Mobile-Friendly Vision Transformer 본문
[ 논문 리뷰 ] MobileViT : Light-Weight, General-purpose, and Mobile-Friendly Vision Transformer
kalelpark 2023. 1. 18. 18:48
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/Awesome-ComputerVision
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com
Abstract
Light weight convolutional Neural Net은 Mobile Vision Task에서 상당히 중요하다. Spatial inductive biases는 약간의 파라미터를 추가하여, 여러 Vision task에서 다양한 Representation을 학습하는 것이 가능합니다. 하지만, 이러한 방법은 Spatially local하다.
Global Representation을 학습하기 위해 ViT를 사용한다. 기존의 CNN과 다르게, ViT는 heavy weight이다.
본 논문에서는 CNN의 강점과 ViT의 강점을 살린 Mobile Vision Task가 가능한지에 대해서 의문을 제기한다. 결국 본 논문에서는 MobileViT를 도입한다. MobileViT는 가볍고, 모바일 장치에서 매우 강력하다. MobileViT는 ViT를 사용하여 정보를 Global하게 처리하는 관점에 대해서 다른 관점을 제시한다.
MobileViT는 CNN과 ViT기반의 Network에서 높은 성능을 보여준다.
Introduction
많은 현실 세계에서는 Visual Recognition을 제약된 장치에서 사용되어야 한다. 효율성을 위해서 ViT 모델은 빠르고 경량화가 되어야 한다. 비록 ViT Model의 크기가 제약된 장치에 맞도록 줄일 필요가 있다. Light-weight CNN은 Mobile Vision task에서 매우 강력하다. 하지만, ViT기반 모델은 장치에서 활용되기에는 상당히 제약되는 부분이 많다. ViT는 매우 무거우며, 최적화하기 어렵다. 그리고 상당한 Data Augmentation이 필요할 뿐만 아니라, Overfitting을 방지하기 위해 L2 regularization이 필요하다.
Mobile Vision task는 제약된 장치에 맞추고, 다양한 task에서 맞추기 위해서 light-weight, low latency 높은 정확도가 요구됩니다.
본 논문은 CNN의 Benefit과 ViT의 Benefit을 결합하여, MobileViT를 도입합니다. 특히 tensor내에 효율적으로 local과 global information을 encoding하기 위해, MobileViT Block을 도입합니다.
MobileViT Block은 Convolution에 local processing을 ViT의 global prrocessing으로 변환합니다.

Related Work
Light-weight CNN, Vision Transformers 관련하여, 설명을 진행한다.
본 논문에서는 Light-weight Vit Model에 초점을 둡니다. general-purpose와 light-weight, mobile-friendly를 CNN과 ViT에 도입하여 MobileViT를 제시합니다.
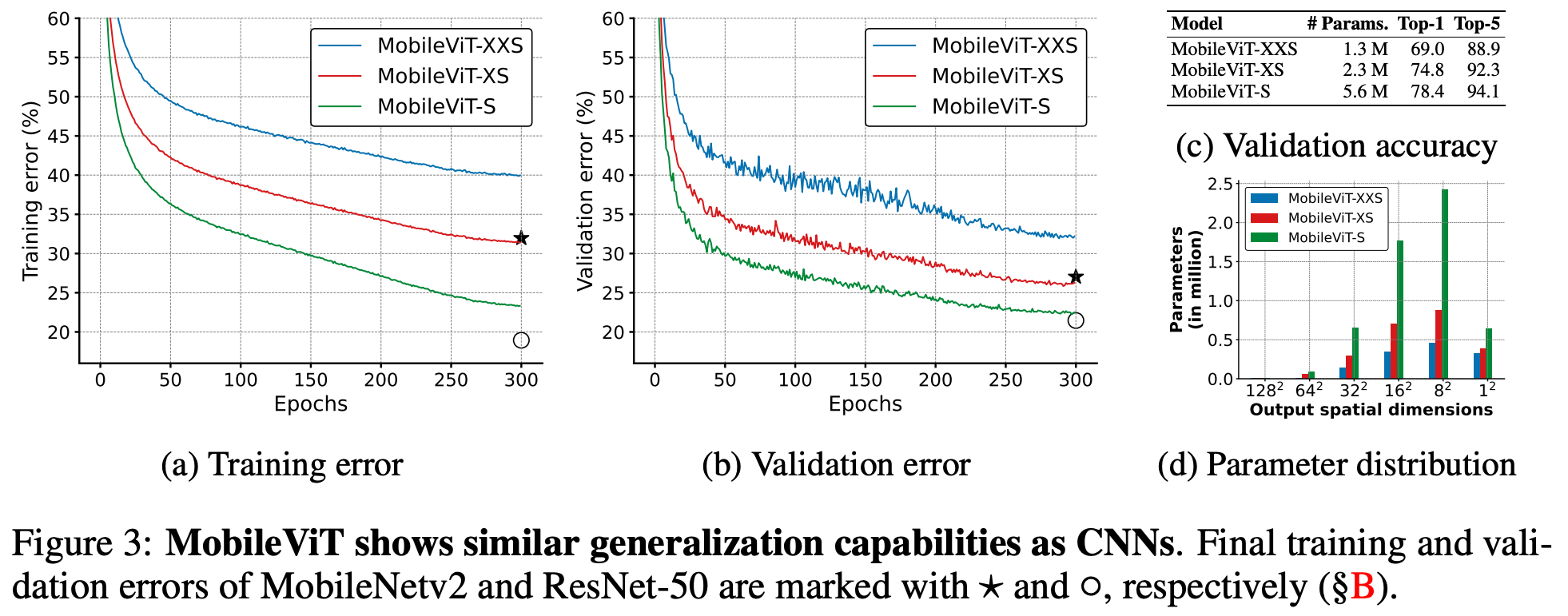
MobileViT : A Light-Weight Transformer
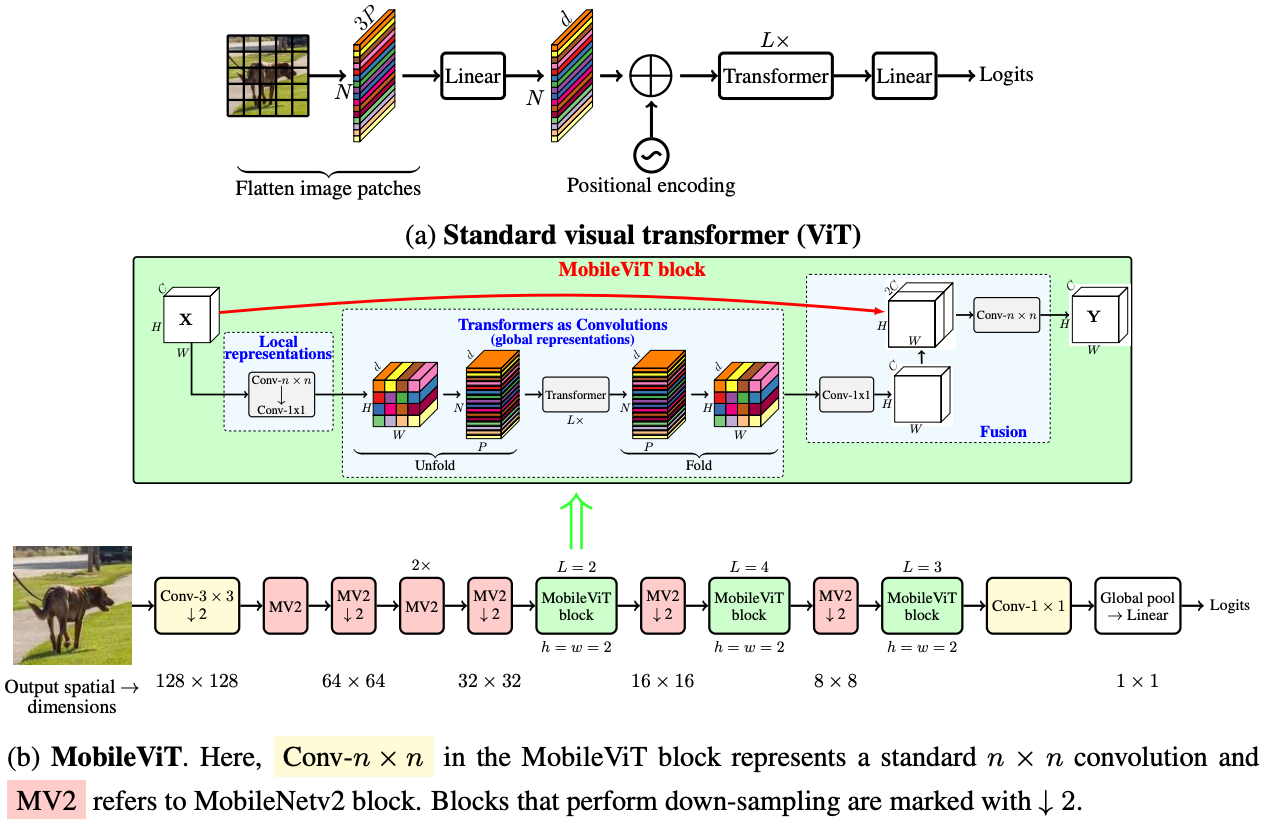
MobileViT Block
MobileViT는 fewer parameter로 local, global information을 모델이 얻는 것을 목표로 하고 있습니다.
input channel의 linear combinations을 학습한 high dimension space로 point-wise convolution으로 tensor를 주입하여 n x n convolutional layer는 local spatial information을 encoding합니다. MobileViT내에서, effective receptive field를 갖기 위한 long-range non-local dependencies를 갖도록 합니다.
MobileViT에서 spatial inductive bias와 global representation을 학습하기 위해서 multihead attention을 이용하여 학습한다.

검고 굵은 색으로 분리된 각 영역은 Overlap되지 않는 patch이고, 각 Patch내 회색 선으로 분리된 공간은 Patch에 속하는 Pixel이라고 보면 됩니다. 왼쪽 하단의 Patch를 보면 파란색 화살표가 주변 Pixel의 종정보를 추출한다. 아래 그림의 경우에는 정가운데 위치한 Patch내에 붉은 색으로 표시된 Pixel은 다른 Patch의 Pixel들의 정보를 취합하는데 사용됩니다.

Relationship to Convolutions
일반적인 Convolutiondms 3가지 operation의 stack으로 볼 수 있다. 1. Unfolding, Matrix Multiplication, folding 순이다.
MobileViT block은 동일한 빌딩 블록을 활용한다는 점에서 Convolution과 유사하다. MobileViT block은 Convolution 내 local processing을 deeper global processing으로 대체한다. 결과적으로 MobileVit는 Convolution이 Transformer로 보일 수 있다. 의도적으로 단순한 모델의 설계는 Convolution 및 transformer를 낮은 수준의 효율적인 구현을 즉시 사용가능하다는 것이다.
Computational cost
MobileViT와 ViT의 multi-headed self-attention의 비용은 O(N^2d), O(N^2d)이다.

Multi-Scale Sampler for Train
MobileViT의 fine tuning없이, multi-scale representation을 학습하고, 학습의 효율성을 개선하기 위해서 우리는 multi-scale training method를 variably-sized batch size로 확장한다.

Experimental Results

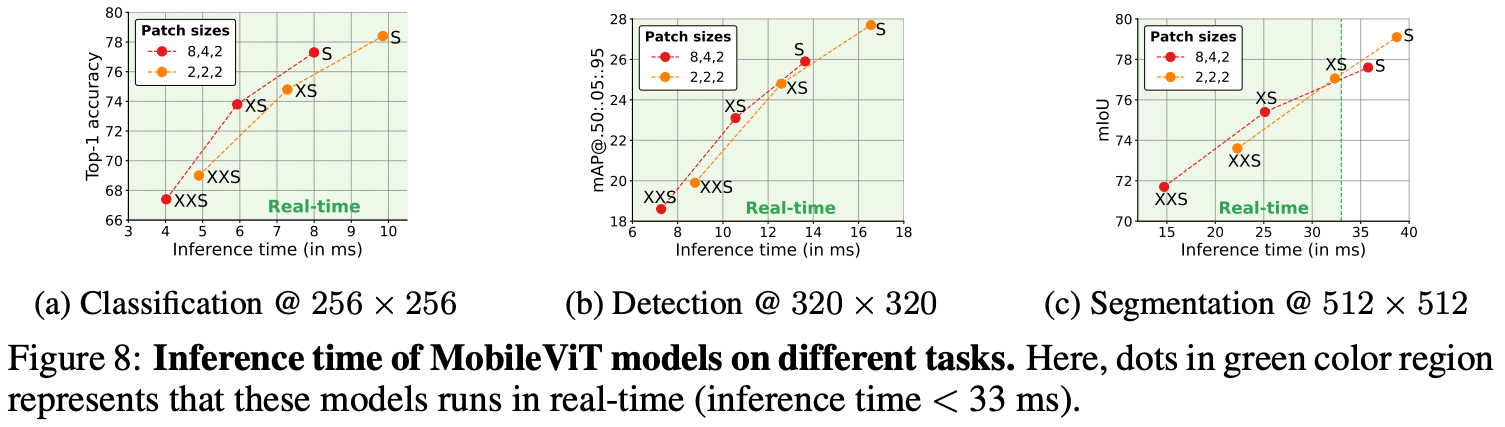
참고
https://arxiv.org/abs/2110.02178
MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
Light-weight convolutional neural networks (CNNs) are the de-facto for mobile vision tasks. Their spatial inductive biases allow them to learn representations with fewer parameters across different vision tasks. However, these networks are spatially local.
arxiv.org
https://pajamacoder.tistory.com/38
https://github.com/chinhsuanwu/mobilevit-pytorch
GitHub - chinhsuanwu/mobilevit-pytorch: A PyTorch implementation of "MobileViT: Light-weight, General-purpose, and Mobile-friend
A PyTorch implementation of "MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer". - GitHub - chinhsuanwu/mobilevit-pytorch: A PyTorch implementation of "...
github.com



