
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 딥러닝
- 자료구조
- FGVC
- CV
- Front
- algorithm
- SSL
- Meta Learning
- pytorch
- web
- 머신러닝
- nlp
- PRML
- FineGrained
- GAN
- Depth estimation
- Python
- clean code
- REACT
- cs
- ML
- 알고리즘
- math
- computervision
- classification
- 3d
- Torch
- dl
- nerf
- Vision
- Today
- Total
KalelPark's LAB
[논문 리뷰] An Image is Worth 16x16 words: Transformers for Image Recognition at Scale 본문
[논문 리뷰] An Image is Worth 16x16 words: Transformers for Image Recognition at Scale
kalelpark 2023. 1. 15. 13:48
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/AI_PAPER
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com
Abstract
최근, NLP에서는 Transformer구조가 일반적인 활용으로써, 자리 매김해왔지만, Vision 분야에서는 잘 응용되지 않았다.
Vision분야에서 Attention을 사용하는 경우, 주로 Convolution Network와 혼합되어 사용되거나, 몇몇 대체되는 식으로 활용되었다.
본 논문에서는 CNN의 의존 불 필요성과 Transformer가 Image Patch들의 Sequence에 적용해 이미지 분류 task에서 매우 잘 동작한다는 것을 증명하였습니다.
Introduction
Transformer의 기반이 되는 Self-attention는 NLP 분야에서 계속해서 활용하였습니다.
주된 접근방식은은 large text corpus에 대해 pre-train한 후, 소규모 task에 fine-tune을 시행하였습니다.
Transformer의 계산효율성과 학장성 덕분에, 100B의 파라미터가 넘는 이전에 생각지도 못한 크기를 모델이 학습하는 것이 가능해졌습니다. 뿐만 아니라, 모델과 데이터가 커져도, Saturating performance가 없습니다.
저자들은 Transformer를 image에 적용하기 위해서, image를 patch 단위로 나누고, 이러한 patches들의 선형적인 embedding Sequence는 Transformer의 Input으로 활용하였습니다.
하지만, 단점으로는 Inductive biases로써, CNN에 내재되어있는 translation equivariance, locality와 같은 성질이 Transformer에는 부족하기 때문에 데이터가 부족한 경우 일반화 성능이 좋지 않습니다.
Method

기존 Transformer는 1차원 Token Embedding Sequence를 Input으로 받습니다.
모델 내부에서 2차원 Image를 다루기 위해서, 를 2차원의 패치들 로 flatten 실시
즉 Patch로 만든 후에 일렬로 Squeeze하는 방식이 필요합니다. Transformer는 내부의 모든 Layer들의 latent Vector의 Size를
D로 통일하였으며, 2차원 Patch들을 다시 1차원으로 flatten하고 linear projection을 거쳐 Mapping해야 합니다.
* 이러한 방법론들을 Patch Embedding이라고 합니다.
실험을 진행하였을 때, Image를 위해 2D-aware position Embedding을 사용하였으나, 유의미한 성능향상을 주지 않아, 1D Embedding을 활용하였습니다.
위의 과정을 통하여, 최종 Embedding Vector들이 나오고, Sequence가 Input으로 사용됩니다.
Transformer의 Encoder에는 Multi-Head Self Attention과 MLP 블록들이 교차되었습니다.
Hybrid Architecture
Raw Image Patches 대신에 CNN의 Feature Map으로부터 Input Sequence가 형성될 수 있습니다.
이러한 Hybrid Model에서 Patch Embedding Projection은 CNN의 FeatureMap으로부터 추출된 패치들에 적용됩니다.
패치들이 공간적 크기, 즉 픽셀 단위를 가질 수 있는데, 이는 Input 시퀀스가 feture Map의 공간차원들을 Flatten한 뒤, Transformer의 차원으로 Projection함으로써 얻어진다는 것을 의미합니다.
- Pixel단위로 Squeeze하여, Transformer에 넣는것과 동일
- CNN을 활용하기에, Spatial 정보도 담깁니다.
Experiments

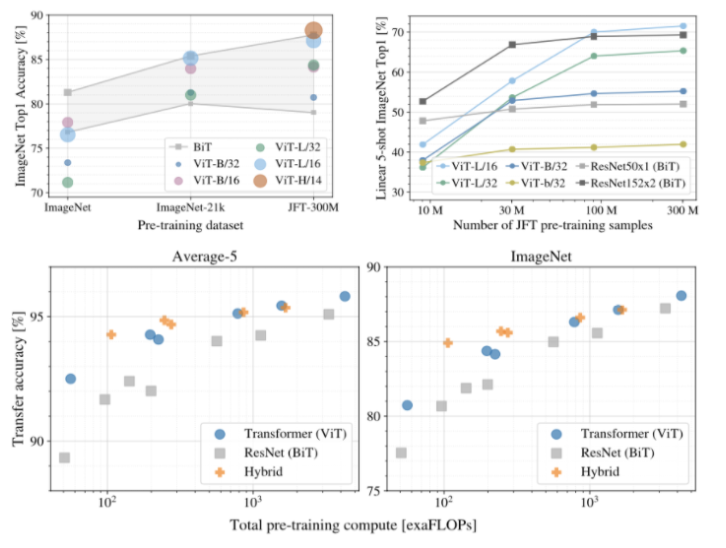
Conclusion
연구진들은 Image Recognition에서 Transformer의 적용을 연구하였다. Image를 Patch의 Sequence로 해석하고, NLP내에서 표준적으로 사용되는 Transformer encoder를 사용하였다. Transformer는 여러 규모로 확장 가능하며, 거대한 규모의 데이터셋에서 놀라운 성능을 보였습니다. 그리고 Vision Transformer는 Image Classification의 여러 Dataset에서 SOTA를 달성하였습니다. ViT를 Scaling한다면, 개선의 여지가 있음을 연구에서 보여주었다.
참고
https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org



