
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 자료구조
- Python
- CV
- math
- 머신러닝
- GAN
- Vision
- ML
- pytorch
- nlp
- 딥러닝
- SSL
- algorithm
- clean code
- Meta Learning
- PRML
- FGVC
- Depth estimation
- Front
- computervision
- dl
- classification
- 3d
- web
- cs
- REACT
- nerf
- Torch
- 알고리즘
- FineGrained
- Today
- Total
KalelPark's LAB
[논문 리뷰] Training data-efficient image transformers& distillation through attention 본문
[논문 리뷰] Training data-efficient image transformers& distillation through attention
kalelpark 2023. 1. 15. 20:37
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/Awesome-ComputerVision
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com
Abstract
본 논문에서는 ImageNet1K로만, 단지 학습하여, 경쟁력있는 Convolution-free transformer를 설명합니다.
1개의 컴퓨터로 학습하는데 3일 미만의 시간이 걸렸으며, 외부 데이터를 사용하지 않고, 높은 성능을 달성하였습니다.
무엇보다도, teacher-student 방법을 Transformer에 도입합니다. 이러한 distilation방식은 teacher의 attention으로부터
student는 학습을 진행합니다.
Introduction
최근에 NLP의 attention 기반의 방법들에서 영감을 받아, ConvNet에서도, 영향력 있는 attention기반의 방법을 사용한다.
최근 몇몇 연구진들은 Vision task를 해결하기 위해, transformer를 기반으로 한 Hybrid architecture를 제안한다.
이전의 ViT모델은 inductivebias가 상당히 크기 때문에, 충분한 데이터가 없으면 generalize하는 능력이 떨어집니다.
본 논문에서는,single gpu 8 node로부터 2~3일 동안 학습을 진행해도, 충분한 성능을 보여주는 ConvNet기반의 모델에 대해서 설명합니다. 단지 ImageNet1K만을 사용하였습니다.
우리의 Data-efficient Image Transformer(Deit)는 상당한 성능을 보여줍니다. Deit는 token-based strategy를 도입합니다.
그것은 일반적인 distillation에 대체된다는 것을 보여줍니다.
Contributes
1. 본 논문에서는 외부 데이터 없이 SOTA와 경쟁할 수 있는 Neural Network를 제시합니다.
2. distillation token을 도입하는 새로운 distillation을 설명합니다.
이것은 class token과 같은 역할을 하지만, teacher이 목표로하는 label을 학습한다는 점에서 다르다.
3. 흥미롭게도, distillation을 통하여, Image Transformer는 another Transfomer보다, 더 많은 것을 학습합니다.
Related Work
The Transformer Architecture
Image Classification는 transformer로부터 많은 영감을 받아 성능을 개선하였다. 예를 들어, Squeeze and Excitation, Selective Kernel, Split-Attention 기법들이 존재합니다.
Knowledge Distillation
Knowledge Distillation 전략은 Strong Teacher Network로부터, soft Labeling의 영향을 받아 student Model을 학습시키는 전략을 위해 사용됩니다.
Teacher's Soft labels은 labels smoothing과 같은 유사한 영향을 끼칠 것이다. 한편으로는 Teacher's Supervision task는 data Augmentation을 고려할 경우, 실제 label과 Image사이에서 오정렬이 발생할 수 있습니다.
KD는 hard way를 포함하는 teacher model을 활용하여, student model에 soft way로 inductive bias를 전이할 수 있습니다.
본 논문에서는 convnet or transformer teacher에 의한 transformer student의 distillation을 연구합니다. 또한 Transformer를 위한 새로운 distillation 방식을 도입하고, 우수성을 입증합니다.
Distillation through attention
본 논문에서는 teacher Model로써 강력한 Image classifier에 접근할 수 있음을 보여줍니다. teacher Model은 ConvNet일수도, Mixture of classifier일 수 있습니다. Image 처리량과 정확도 사이에서의 tradeoff를 통하여 비교함으로써, Transformer에서 CNN으로 대체하는 것은 이득이 될 수 있습니다.
Soft Distillation
Teacher, Student의 Model의 softmax에서의 Kubllback-Leibler를 최소화해야 합니다.
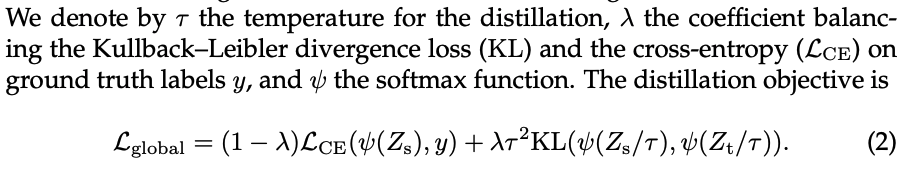
Hard distillation
teacher의 hard deicision을 true label로 받아들이는, distillation 방식을 설명합니다.
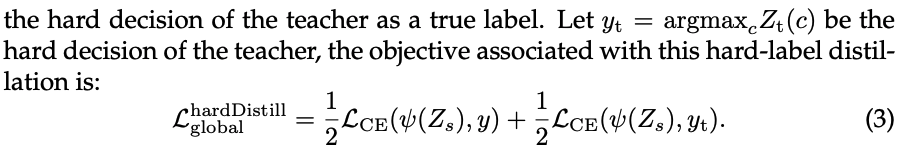
Image를 고려하였을 때, teacher Model과 관련된 Hard label은 Data Augmentation에 의존되어, 변경될 수 있습니다.
이러한 방식은 이전의 방법보다 더 좋은 선택일 수 있음을 보여줍니다. 왜냐하면 parameter가 따로 필요하지 않고, 개념적으로 단순하기 때문입니다.
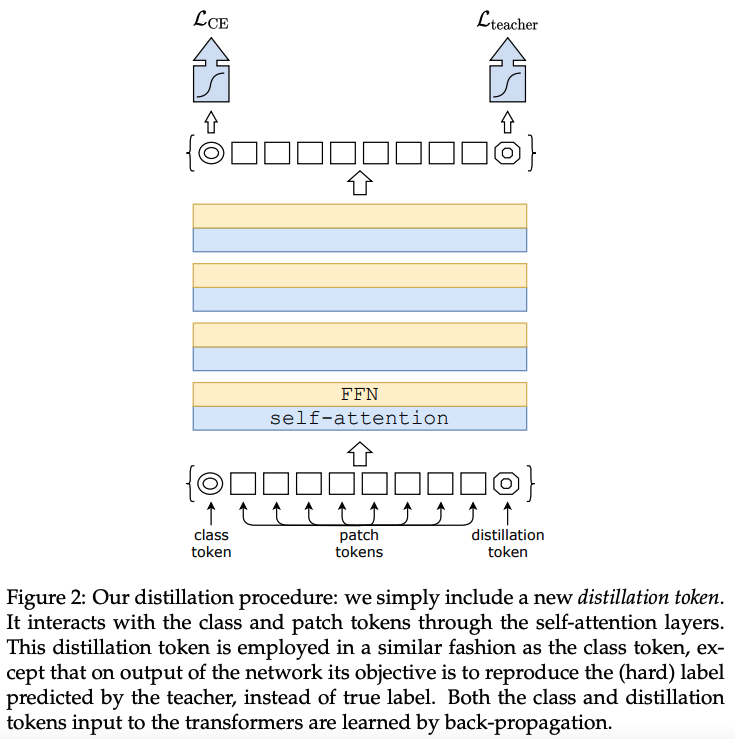
Distillation token
하단의 이미지에 초점을 두어 설명합니다. 초기의 Embedding을 진행할 때, distillation toekn을 도입합니다.
distillation token은 class token과 유사합니다. 이것은 self-attention을 통한 또 다른 Embedding과 상호작용합니다.
그리고 Network의 last layer 이후에 출력됩니다. 그것의 목표는 손실의 증류 성분에 의하여 주어집니다.
Class Embedding을 보완하면서, Distillation Embedding은 우리의 모델이 teacher Output으로부터 학습하도록 합니다.
비록 초기에는 random으로 초기화 했을 지라도, training을 진행할 때, same vector로 수렴하게 됩니다.
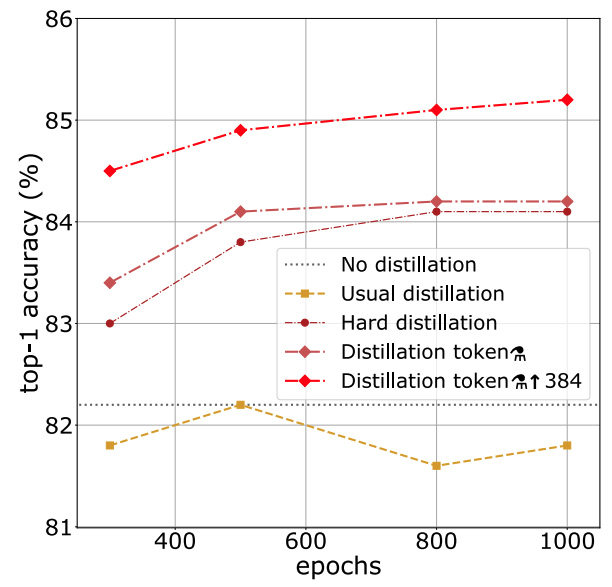
뿐만 아니라, Deit의 전략은 일반적인 Distillation보다 상당한 성능 개선을 보여줍니다.
Experiments
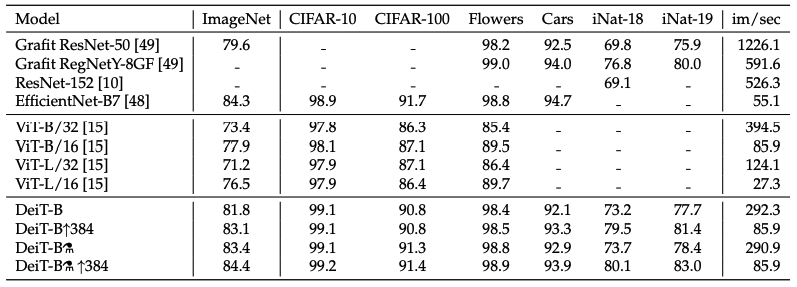
Conclusion
본 논문에서는 수 많은 데이터가 요구되지 않는 Image Transformer인 Deit를 도입합니다. 특히 Distillation 절차와 Training 전략덕분에 상당한 성능향상을 얻을 수 있었습니다.
Deit(Data Efficient Image Transformer)를 위해 새로운 token 외에 중요한 architecture를 도입하지 않고, 기존의 데이터 증강 및 정규화 전략을 사용합니다.
참고
https://arxiv.org/abs/2012.12877
Training data-efficient image transformers & distillation through attention
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification. However, these visual transformers are pre-trained with hundreds of millions of images using an expensive infrastructure, ther
arxiv.org
Training data-efficient image transformers & distillation through attention
Training data-efficient image transformers & distillation through attention Recently, neural networks purely based on attention were shown to addressimage understanding tasks such as image classification. However, these visualtransformers are pre-trained w
milkclouds.work



