
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- ML
- nlp
- 머신러닝
- REACT
- classification
- SSL
- Depth estimation
- math
- 딥러닝
- clean code
- Meta Learning
- GAN
- Front
- nerf
- FineGrained
- 3d
- cs
- dl
- PRML
- 자료구조
- Torch
- Vision
- Python
- 알고리즘
- CV
- web
- algorithm
- computervision
- FGVC
- pytorch
- Today
- Total
KalelPark's LAB
[논문 리뷰] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks [ 2019 ] 본문
[논문 리뷰] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks [ 2019 ]
kalelpark 2022. 12. 6. 23:45
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/AI_PAPER
GitHub - kalelpark/AI_PAPER: Machine Learning & Deep Learning AI PAPER
Machine Learning & Deep Learning AI PAPER. Contribute to kalelpark/AI_PAPER development by creating an account on GitHub.
github.com
Introduction
✨ 해당 논문은 연구에 따른 new scaling method을 적용한 EfficientNet을 소개합니다.
논문에서는 Model을 scaling하고 Network의 Depth, width, resolution의 조절한다면, better performance를 낸다고 말합니다.
이러한 방법은, MobileNet, ResNet을 통하여 증명되었으며, 단순하고, 뛰어난 compound coefficient를 사용하여, 깊이/높이/해상도의 모든 차원을 균일하게 확장합니다.
지금까지 ConvNets을 scaling up하는 과정은 제대로 이해되지 않았으며, 일반적인 방법으로 깊이, 차원, 이미지의 크기 중에서 한가지만 scale up하였습니다.
2~3차원으로 임의로 확장하는 것이 가능할지라도, 지루한 수동 조정이 필요하며, 차선의 정확도와 효율성을 나타내는 경우가 많습니다.
정확성과 효율성을 달성할 수 있는 일반화된 ConvNet ScaleUp 방법에 대한 질문을 통하여 연구하였을 때, Network의 Depth/width/resolution의 균형을 맞추는 것이 매우 중요하다는 것을 보여주었으며, 그러한 균형은 차원을 일정한 비율로 확장하기만 하면 달성할 수 있다고 보았다.
[ A는 CNN BaseModel이며, B~D는 관행적으로 이루어진 Scaling 방식이고, E는 새로운 방식이다. ]
만약, 우리가 $2^N$ 많은 Computational resource를 사용한다면,
단순히 $a^N(depth) B^N(width) r^N(imagesize)$ 를 조절하면 됩니다.
$a, B, r$는 Original small model내의 small grid에 의하여 걸정나는 constant coefficients입니다.
Compound Model Scaling

이전의 ConvNet은 F를 찾는데 중점인 것과는 다르게, Model Scaling은 F의 변화가 없이, Width, Length, Resolution(H,W)를 확장하는데 중점을 둡니다.
이때, Width, Length, Resolution의 Scale을 찾을 때, 제각각의 Scale을 사용하면, 상당히 오랜 시간이 걸리므로, Constant Ratio 즉 일정한 비율을 모든 layer에 적용하여 제안합니다.
즉, 주어진 제약 조건 (fixed f , Constant Ratio)에서 Model Accuracy를 최대화하는게 목표입니다.
Scaling Dimension
Depth, Width, Resolution이 각각에 의존하기에 해결에 어려움이 있어, 이전 연구에서는 한 가지의 Dimension만을 변경해왔습니다.
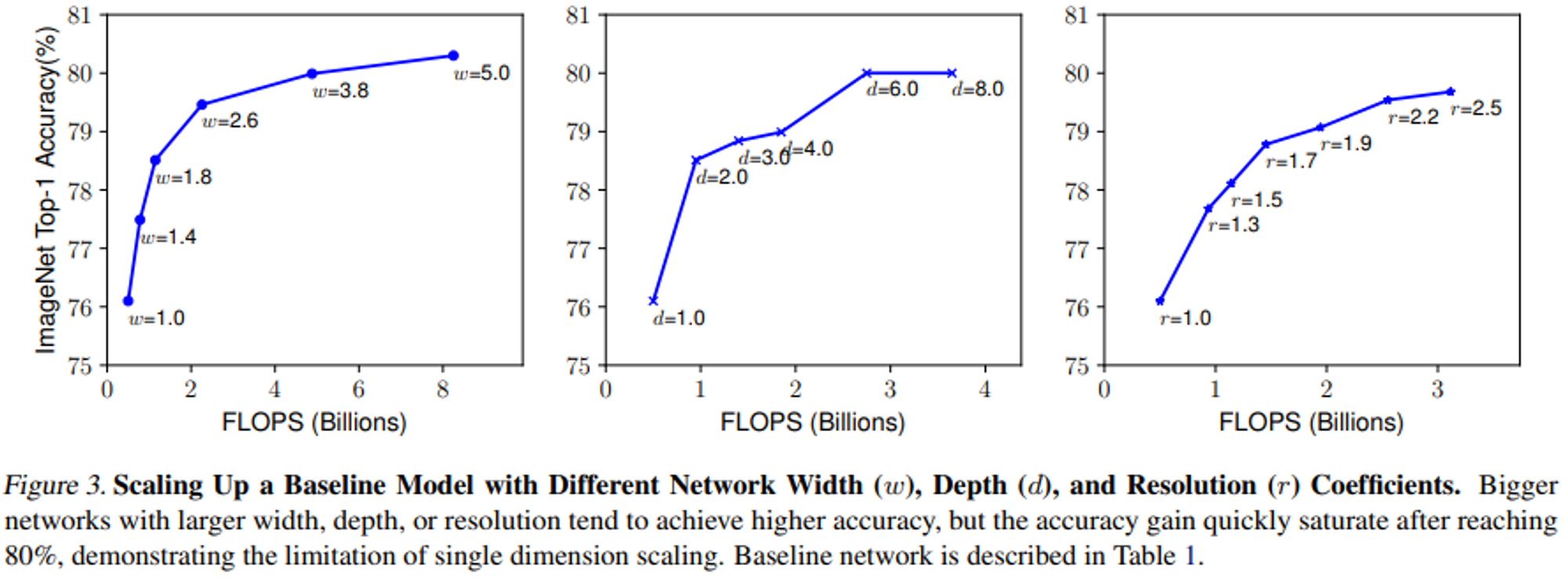
Compound Scaling
다양한 실험을 통하여, Width, Depth, Resolution간의 균형을 맞추는 것이 중요함을 보여줍니다.

Compound Coefficient로 Width, Depth, Resolution를 균일하게 Scale하는 방법을 보여줍니다.
Compound Coefficients의 경우 사용자가 사용가능한 만큼 지정하면 됩니다. 일반적인 Convolution연산에서는 FLOP은 $d, w^2, r^2$ 의 비율로 계산을 합니다.
$FLOP = (d, w^2, r^2)^ ϕ$ 로 계산되며, $dw^2r^2 ≈2$ 의 조건에 의해 $FLOP$이 대략 $2^ϕ$ 증가합니다.
EfficientNet Architecture
💡 Scaling method을 활용해서, EfficientNet의 effectivness를 증명할 것입니다.
Accuracy와 FLOPS를 최적화는 Multi-Objective neural Archtiecture로부터 영감을 받아, Base Network을 개발하였습니다.
EfficientNet-B0의 주요 Block은 mobile inverted bottleNeck인 MBConv2로 생성되었으며, Squeeze-and-excitation optimization을 사용하였습니다.
EfficientNet-B0을 기초로 시작하여, Compound Scaling 방법을 2단계 거쳐 적용하였습니다.
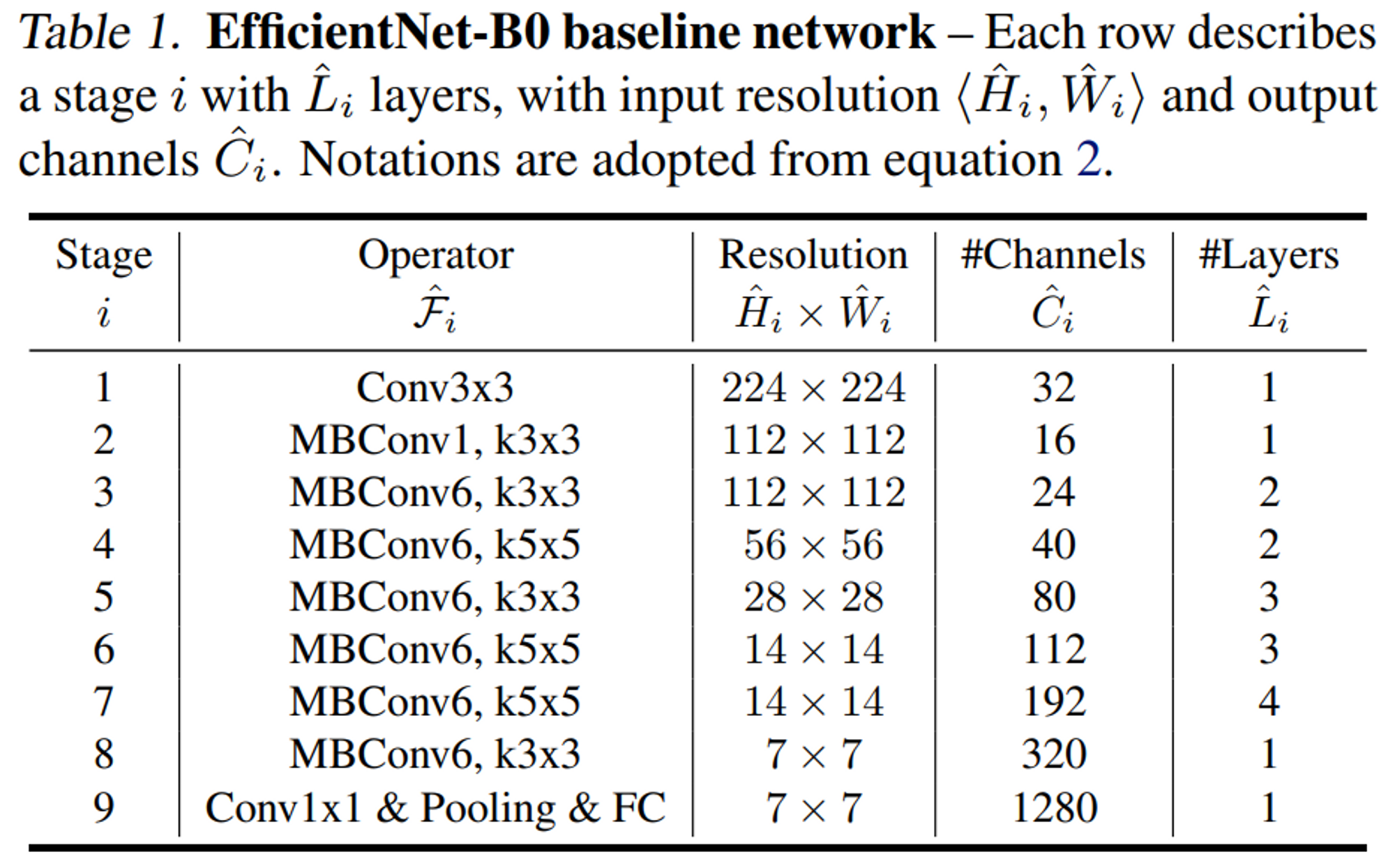
- STEP1 : ϕ를 1로 고정한 후, 제한 조건 내에서 GridSearch를 활용하여, $D, W, R$ 를 구합니다. EfficientNet-B0의 경우 $D=1.2$, $W=1.1$, $R =1.15$ 가 최적의 값이였다.
- STEP2 : D, W, R을 상수로 고정하고, ϕ를 증가시키면서, 네트워크의 scale을 확장하면서 EfficientNet B1~B7까지의 모델을 얻었습니다.
Experiments
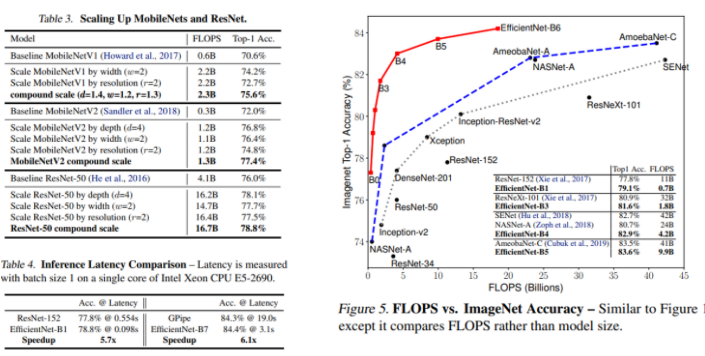
Conclusion
본 논문에서는 체계적으로 ConvNet을 확장 및 신중하게 width, depth, resolution의 identifty를 균형을 조절합니다. Compound Scaling Method의 Powered에 의하여, EfficientNet의 effectively를 증명하였습니다.
Reference
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing n
arxiv.org
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/AI_PAPER
GitHub - kalelpark/AI_PAPER: Machine Learning & Deep Learning AI PAPER
Machine Learning & Deep Learning AI PAPER. Contribute to kalelpark/AI_PAPER development by creating an account on GitHub.
github.com



