
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 알고리즘
- Vision
- 딥러닝
- REACT
- web
- FineGrained
- 자료구조
- clean code
- nlp
- CV
- pytorch
- Torch
- Python
- 머신러닝
- SSL
- Meta Learning
- Depth estimation
- nerf
- PRML
- math
- 3d
- algorithm
- GAN
- computervision
- cs
- classification
- dl
- FGVC
- ML
- Front
- Today
- Total
KalelPark's LAB
[ PRML ] Ch1. Probability Theory, Model Selection 본문

PRML
Probability Theory
- Pattern Recognition 분야에서 중요한 개념 중 하나.
- Uncertainty가 발생하는 이유
- 충분하지 못한 데이터
- 관찰된 데이터에 포함된 노이즈 문제
Probability Theory
- 불확실성을 정확하고 정량적으로 표현할 수 있는 수학적 프레임워크 제공
Decision Theory
- 불완전하고 모호한 정보로부터 최적의 예측안 마련 가능
Likelihood에서 Frequentist 와 Bayesian과의 차이
Frequentist
- Maximum Likelihood가 대표적인 추정자(estimator)로 보통 p(D | W)를 최대로 만드는 W를 찾는 것이다.
(여기서 w는 알려지지 않은 고정된 파라미터 값이고, 이를 추정합니다.)
- 기계학습에서는 주로, log-likelihood를 사용합니다.
Bayesian
- 파라미터 w를 랜덤 변수로 간주하고, 확률분포로써 사용합니다. 그리하여, 확률 함수를 통하여 얻습니다.
고정된 값이 아니고, 분포이기에 덜 극단적인 결과를 얻을 수 있습니다.
* 기타 다른 내용들은 아래에 필기로 더 상세하게 작성해두었습니다.
Probability Theory
Maximum Likelihood란?
likelihood란 데이터가 특정 분포로부터 만들어졌을 확률을 의미합니다. 예를 들어, X = (1, 1, 1, 1)이라는 데이터가 존재할 때, 아래의 분포가 있다고 가정을 합니다.

데이터는 당연히, 왼쪽 분포를 따를 확률이 높습니다. 이런 상황에서 우리는 왼쪽 분포의 데이터 X에 대한 likelihood가 높다고 표현할 수 있습니다. (하단의 수식은, 0를 파라미터로 갖는 분포를 의미합니다.)

즉, Maximum Likelihood는 모수적인 데이터 밀도 추정 방법으로써 파라미터 θ로 구성된 어떤 확률 밀도 함수 P(x|θ)에서 어떤 데이터 x를 관측했흘 때, θ를 추정하는 방법이다.
구하는 방법은 간단하다. 각 데이터 x를 각각 확률밀도 함수로부터 나왔을 가능성을 다 곱한 것을 활용하는 것이다. 곱하는 이유는 모든 데이터가 각각 독립적이기 때문이다. 이 likelihood를 최대화하는 θ 값을 찾는 과정을 Maximum likelihood라고 합니다. 일반적으로 log를 씌오 log likelihood라고도 합니다.
모 평균을 기반으로 미분을 하였을 때, MLE에서의 평균과 분산을 구하는 것이 가능합니다.
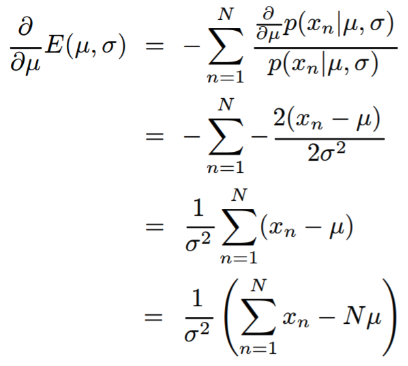

Model Selection
일반적으로 cross validation을 활용합니다.
- 임의로 고른 학습 집합을 제외한 나머지는 테스트 집합으로 활용하여, 학습을 진행합니다. 학습 집합의 개수 만큼 학습을 진행
- 학습 데이터에만 종속적이고, 오버피팅으로 인한 bias가 발생되지 않은 모델의 parameter를 찾는것이 목표입니다.
- AIC(Akaike information criterion)라는 기법을 사용하여, 적은 파라미터를 추정하기도 합니다.

'Data Science > PRML' 카테고리의 다른 글
| [ PRML ] Ch2-1 supplementary materials (0) | 2023.05.06 |
|---|---|
| [ PRML ] Ch2-1 Binary Variables (1) (0) | 2023.05.06 |
| [ PRML ] Ch1. The Infomation Theory (0) | 2023.05.05 |
| [ PRML ] Ch1. The Decision Theory (0) | 2023.05.04 |
| [ PRML ] Ch1. The Curse of Dimensionality, The Decision Theory (0) | 2023.05.03 |



