
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- computervision
- pytorch
- cs
- ML
- 알고리즘
- GAN
- Depth estimation
- classification
- math
- 머신러닝
- Torch
- FineGrained
- Vision
- CV
- Front
- dl
- Python
- clean code
- nlp
- algorithm
- Meta Learning
- PRML
- nerf
- 자료구조
- 3d
- 딥러닝
- FGVC
- SSL
- REACT
- web
- Today
- Total
KalelPark's LAB
[ 논문 리뷰 ] Improving Unsupervised Image Clustering With Robust Learning 본문
[ 논문 리뷰 ] Improving Unsupervised Image Clustering With Robust Learning
kalelpark 2023. 2. 9. 21:55
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com
Abstract
Unsupervised Clustering 방법론은 기존의 학습방법을 대체하기 위해 도입되지만, 잘못된 예측과 안좋은 결과를 가져온다. 이러한 문제를 극복하기 위해 강건한 모델인 RUC롤 설명합니다. RUC(Robust Unsupervised Clustering)은 잘못 분류한 데이터의 라벨을 변경하고, 잘못된 예측을 완화시킵니다.
Model은 module처럼 쉽게 다른 Clustering에 붙여 활용할 수 있으며, 성능 향상에 기여합니다.
Introduction
본 논문에서는, 이전의 Clustering방법론들의 단점들을 언급하고, RUC(Robust Learning for Unsupervised Clustering)를 제안합니다. RUC는 기존 클러스터링의 잘못된 레이블을 포함할 수 있는 노이즈가 많은 데이터 세트를 활용하여, 잘못 정렬한 지식을 수정합니다. 우리는 불명확한 데이터를 제거하고, 손실을 보정합니다.
위 방법은 Label smoothing과 co-training을 활용하고, 불명확한 label로부터 wrong gradient signal을 감소시킵니다. 본 논문에서는 잘못 라벨링한 내용들을 필터링하기 위해 confidence-based, metric-based, hybrid strategies를 사용합니다. 첫 번째 전략은 일반적인 clustering model로부터의 높은 확률을 가진 sample을 clean set으로 고려하고, low confidence sample은 제거합니다. 두 번째 전략은 깨끗한 데이터를 탐지하기 위해 Unsupervised embedding으로부터 유사도 기반 전략을 사용합니다.
세 번째 전략은 2가지 방법을 결합하고, 두 전략에 따라 신회할 수 있는 샘플을 선택합니다.
이후, MixMatch를 활용한다음, label smoothing과 block learning을 사용합니다. 마침내 학습하는 동안 co-training architecture에서 unclean sample로부터 noise를 완화할 뿐만 아니라 성능도 증가시킨다.
Contributes
1. 제안된 알고리즘 RUC는 retraining과 예측 회피를 통하여, 기존의 Unsupervised Clustering Model의 성능향상에 기여합니다.
2. 기존의 방법론의 성능 향상에 기여합니다.
3. 제안된 학습과정을 거치면 정확도를 상당히 개선시킬 수 있습니다.
Method
RUC는 misprediction을 수정하기 위한 기존의 clustering method와 함께 사용할 수 있는 add-on Module이다. 핵심 아이디어는 노이즈가 많은 데이터를 활용하고, 약한 군집화 과정을 수정하기 위해 학습하고, 강건한 학습으로부터의 기술이다.
첫 번째로, Clean과 Unclean 두개의 집합으로 traininig data로 나눕니다. 이후 각각의 데이터를 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터로 나눕니다. 이후, label data와 unlabel data를 재조정하면서, semi supervised learning으로 다시 학습시킵니다. 강건한 학습을 위해 semi-supervised class assignment으로 학습합니다.

Extracting Clean Samples
Clean data와 unclean data를 활용함에도 불구하고, pseudo label에 대한 ground truth가 없기 때문에 정확하게 Sampling하는 것은 솔직히 어렵습니다. 하지만, Selection strategy를 하기 위해 3가지 방법론을 연구합니다.
1) Confidence-based, 2) metric-based, 3) hybrid
Confidence-based strategy
Unsupervised classifier의 confidence score기반으로 clean sample에 선택하는 방식이다. training sample을 고려하여, threshold를 넘는 것에 대해서만 PseudoLabel을 활용한다. 하지만, 과잉적합되는 경우가 있으므로, 각 클래스의 전형적인 예시만을 신뢰합니다. Threshold는 불확실한 데이터는 무시하기 위해 최대한 높이는 것이 중요합니다.
Metric-based strategy
메트릭 기반 접근법은 감독되지 않은 방식으로 학습된 추가 임베딩 네트워크를 활용하고, Pseudolabel의 신뢰성을 측정합니다. KNN을 사용하여, PseudoLabel과 같은 것만을 CleanLabel로 활용합니다.
Hybrid-based strategy
Confidence와 Metric기반의 방법론에서 신뢰할 수 있는 데이터를 Sample로 활용하는 것이다. 나머지는 Unlabel 데이터로 활용합니다.
Experiment

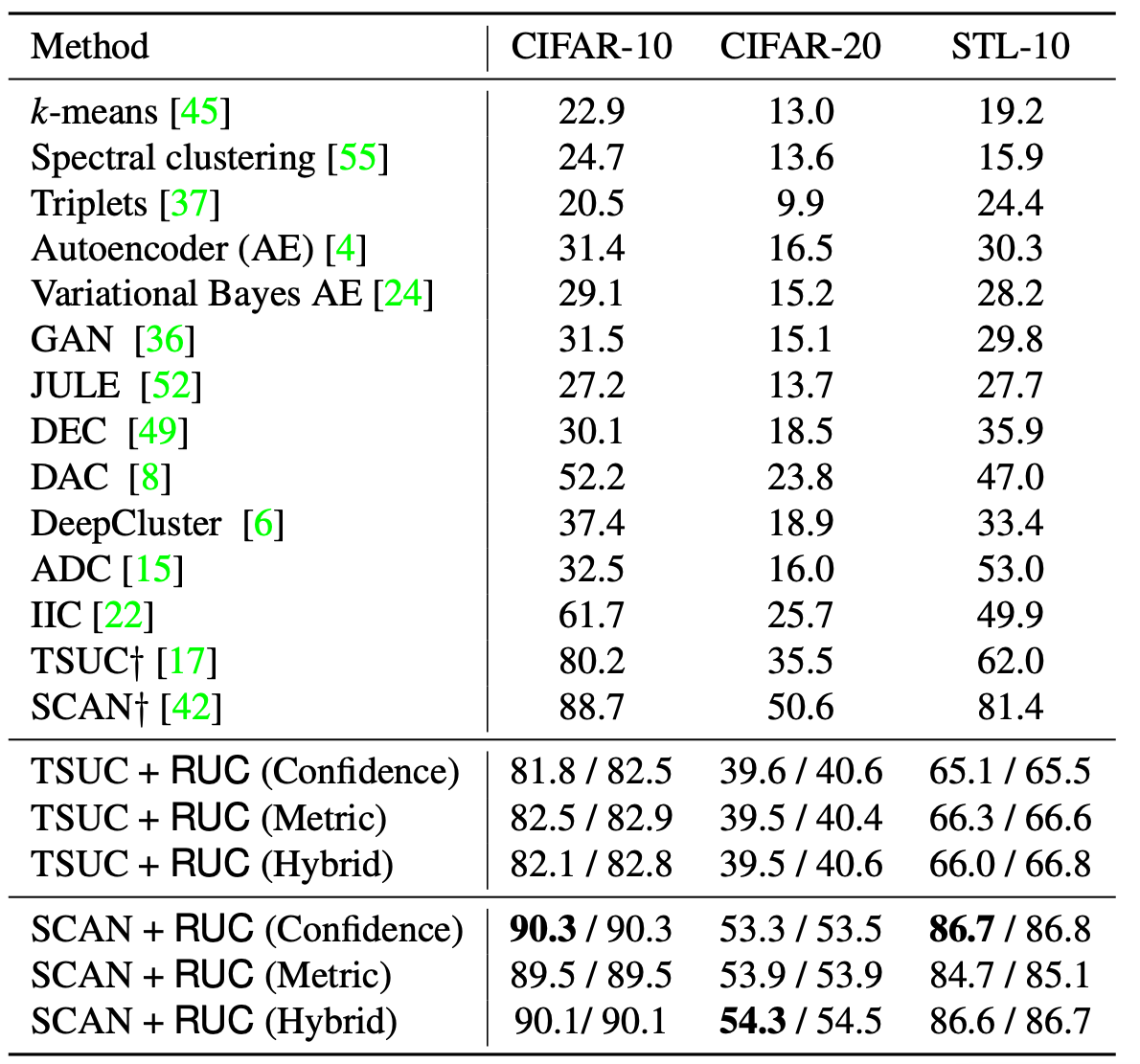

Reference
https://arxiv.org/abs/2012.11150
Improving Unsupervised Image Clustering With Robust Learning
Unsupervised image clustering methods often introduce alternative objectives to indirectly train the model and are subject to faulty predictions and overconfident results. To overcome these challenges, the current research proposes an innovative model RUC
arxiv.org



