
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- web
- FineGrained
- GAN
- classification
- FGVC
- 머신러닝
- math
- 딥러닝
- SSL
- Depth estimation
- 3d
- dl
- nerf
- Python
- CV
- REACT
- cs
- Front
- Torch
- nlp
- Meta Learning
- computervision
- 자료구조
- pytorch
- Vision
- PRML
- algorithm
- 알고리즘
- ML
- clean code
- Today
- Total
KalelPark's LAB
[ 논문 리뷰 ] How Well Do Self-Supervised Models Transfer? 본문
[ 논문 리뷰 ] How Well Do Self-Supervised Models Transfer?
kalelpark 2023. 2. 6. 16:56
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/Awesome-ComputerVision
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com
Abstract
Self Supervised Learning은 계속해서 발전해왔지만, 현재 이용 가능한 모델에 대한 대규모 비교는 없었다.
본 논문에서는 여러 task를 포함하여, Self Supervised Learning 방법론을 비교합니다.
본 논문에서는 Supervised Learning과 비교를 진행하고, 대부분의 경우 Self Supervised Learning이 transfer Learning시 상당한 성능향상을 기여한다는 것을 보여줍니다. 하지만, Single Self Supervised Learning이 지배적이지 않아, 사전 훈련이 여전히 해결되고 있지 않음을 시사합니다.
Introduction
한번 학습이 된 이후에, CNN Representation들은 feature를 다시 활용함으로써 새로운 task에서 더 많은 데이터를 효율적으로 학습합니다. 하지만, SSL은 Supervised Learning이 비해 성능이 떨어집니다. 하지만 최근에 계속된 발전을 함으로써 fully supervised Learning을 뛰어넘습니다. 이는 추후 ComputerVision의 패러다임에 집중될 수 있는 희망을 가져옵니다.
ComputerVision에 새로운 접근방식에 나타남에 따라, Self Supervised Learning의 중요성이 점정 증가하고 잇으면서, 경험적 성과 및 벤치마킹에 대한 관심이 증가하고 있습니다. Self Supervised Learning을 비교하기에는 상당히 어렵다. 왜냐하면, 접근법들이 각각 다르기 때문이다.
본 논문에서는 각각의 self supervised Learning을 여러 방법론에 적용하고, 다양한 Dataset에 적용하여 비교합니다.
Contributes
- Self Supervised Learning은 색상정보보다는 공간적 정보에 집중을 두어 이해하는 경향이 있습니다. 이러한 이유는,
Self Supervised Learning은 여러 Augmentation을 적용하기 때문이라고 한다.
- SwAV와 DeepClusterV2 방법론이 ImagfeNet에서 가장 좋은 성능을 보인다. 하지만, Medical skin image와 같은 경우에는 성능 저
하를 보여줍니다. 이를 통하여, 아직 보편적으로 적용하기엔느 힘들다는 것을 보여줍니다.
- Few shot을 제외하고는 Supervised Learning의 성능을 뛰어넘는 다는 것을 보여줍니다.
Related Work
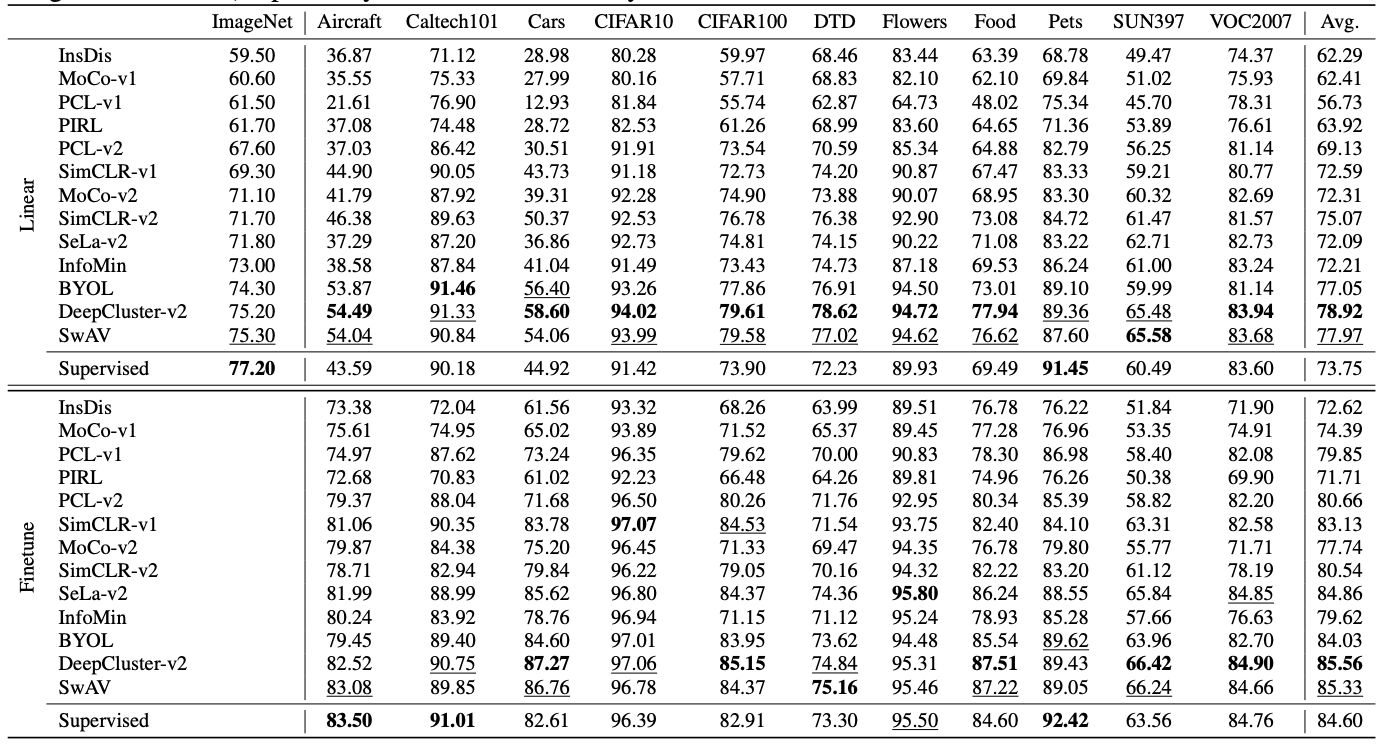
Preliminaries
본 논문에서는 여러가지 Represetation Learning Method를 제안합니다. 본 논문에서는 13가지 방법론을 활용합니다.
MoCo, PIRL, SimCLR, InfoMIN, BYOL, DeepCluster, SwAV 등등 본 논문에서는 각각의 논문에서의 모델이 다르고, augmentation이 다르므로, 통용할 수 있는 augmentation을 사용하고, ResNet50 backbone을 활용합니다.
Does better ImageNet performance lead to better performance on downstream task?
Introduction에서 언급했다시피, 다양한 dataset 혹은 구체적인 task에서도 적용가능한지 의문이라, 본 논문에서는 Pearnson and Spearman과의 상관관계를 비교하였다.
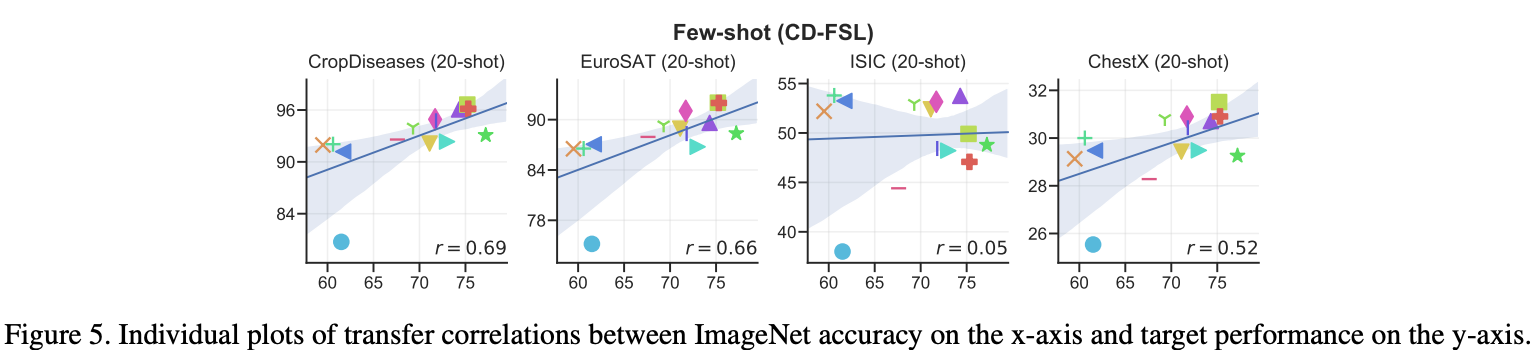
공간적 정보에 민감한 task의 경우 SimCLR과 BYOL이 상관관계가 낲다는 것을 보여주며, ISIC2018의 경우 비교하기에 상당히 모호하다는 것을 보여줍니다. 왜냐하면, ISIC의 경우 Spatial보다는 Color에 조금 더 초점을 두는 경향이 있기 때문입니다.
What information is retained in features?
Self Supervised Learning시, 어떤 정보가 Embedding되는지 연구하는 것은 상당히 중요합니다.
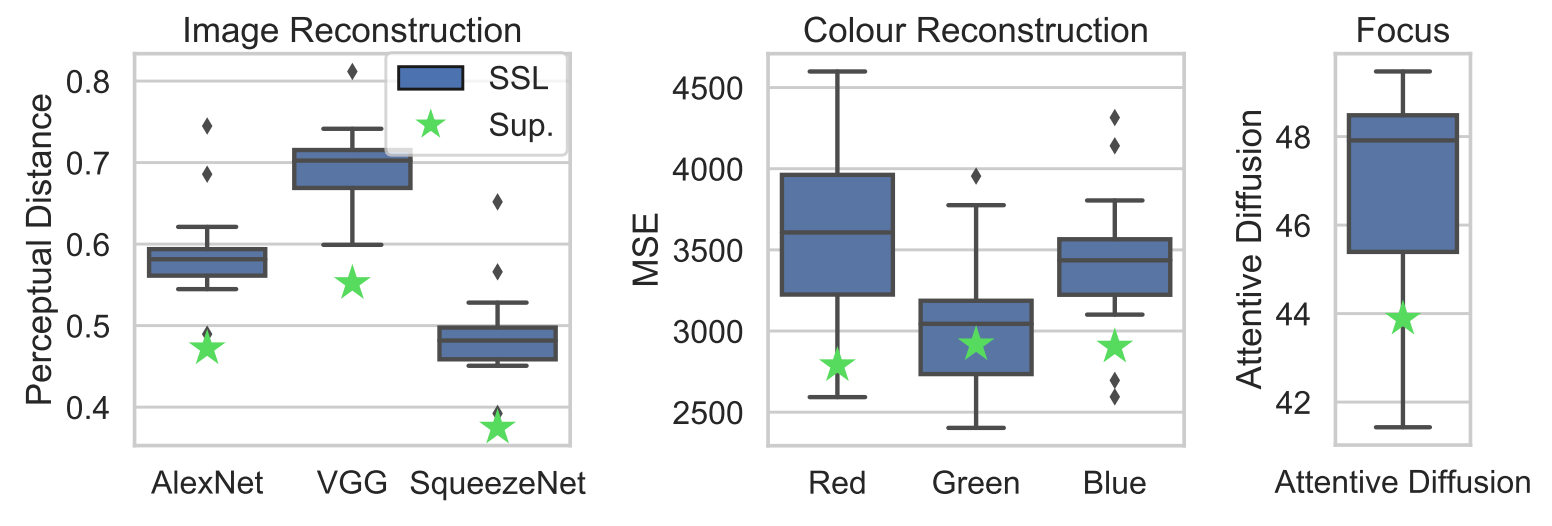
색상에 대해 쉽게 인식을 못하는 이유는, 여러 augmentation을 적용하기 때문이라고 한다. 그로 인하여, 불변하는 색상들에만 특징을 잘 파악한다는 것을 알 수 있었습니다. 그러므로, 색상이 중요한 결정요소인 경우에는 Self Supervised Learning의 방법을 택할 때 상당히 주의를 해야 합니다.
Discussion
본 논문에서는 다양한 Dataset에서 평가를 하고 비교를 진행합니다. 본 논문에서는 3가지를 증명합니다.
1. Self Supervised Learning은 Supervised Learning의 성능을 뛰어넘습니다.
2. ImageNet1K에서의 성능은 natural Image task에서도 비슷한 성능을 나타낸다는 것을 증명합니다.
하지만, ImageNet1K와 다르게 unstructed image recognition에서는 상당한 제한이 있음을 알 수 있습니다.
그러므로, 아직까지는 ImageNet1K에서의 Self Supervised Learning 방법론은 아직까지 다른 task에 보편적으로 활용하기에는 상당히 제한적입니다. 추후의 연구에서는 다양한 데이터 세트를 고려한 실험을 해야함을 향후 작업에 알립니다.
Reference
https://arxiv.org/abs/2011.13377
How Well Do Self-Supervised Models Transfer?
Self-supervised visual representation learning has seen huge progress recently, but no large scale evaluation has compared the many models now available. We evaluate the transfer performance of 13 top self-supervised models on 40 downstream tasks, includin
arxiv.org



