
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Vision
- FGVC
- GAN
- web
- Depth estimation
- nerf
- 딥러닝
- 알고리즘
- Torch
- computervision
- Python
- cs
- algorithm
- pytorch
- classification
- nlp
- Front
- FineGrained
- 3d
- Meta Learning
- PRML
- ML
- SSL
- dl
- 머신러닝
- 자료구조
- clean code
- math
- REACT
- CV
- Today
- Total
KalelPark's LAB
[논문 리뷰] VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning 본문
[논문 리뷰] VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
kalelpark 2023. 3. 12. 14:00
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/Awesome-ComputerVision
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com
Abstract
최근의 방법론은, 2개의 이미지로부터 얻은 embedding된 vector간의 관계를 구하고자 하였다. VICReg은 2개의 정규화항을 임베딩에 별도로 적용하여, 정보가 붕괴되는 것을 피하는 방법을 제시합니다. VICReg는 branch, batch normalization, feature-wise, output 등등이 필요하지 않습니다.

VICReg : INTUITION
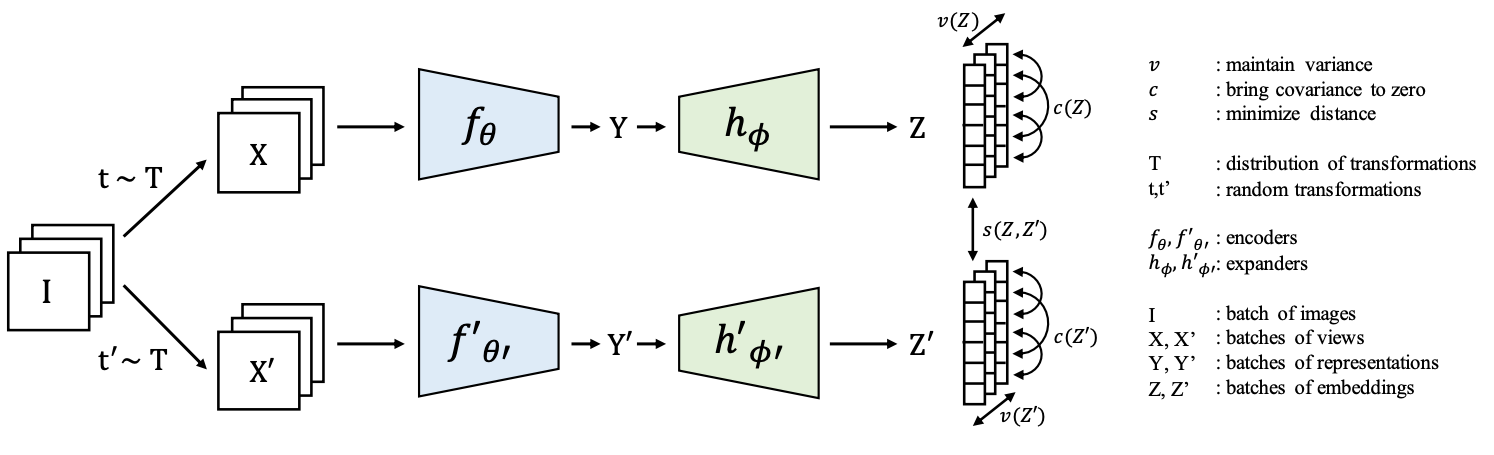
동일한 이미지로부터 얻은 embedding vector는 최소화하고, Batch에 대한 임베딩 변수의 분산이 threshold이상으로 유지되도록 합니다. 공분산은 0을 나타나도록 합니다. Embedding 시, 3개의 fully connected layer를 사용합니다. 이는 이름에서 설명하는 것과 같이
Variance, Invariance, Covariance를 나타냅니다.
Invariance : 임베딩된 Vector사이의 distance를 나타냅니다.
Variance : threshold 위에 임베딩된 각 변수의 표준편차를 어느정도 유지하기 위해 사용합니다.
Covariance : 모든 Embedding된 변수사이의 쌍의 공분산을 0으로 attract하기 위해 사용됩니다.
임베딩된 변수사이의 역상관성으로 활용되고, 높은 상관관계를 띄는 정보들은 붕괴되는 것을 방지합니다.
* 본 논문의 주된 기여로는,
Variance preservation term으로부터, Embedding vector가 0으로 수축되는 것을 방지합니다.
Covariance는 BarlowTwins의 method를 사용하고, 정보가 무너지는 것을 방지합니다.
여기서도, doesn't를 많이 언급합니다.
- does not require that the wieghts of the two branches be shared, not that the architectures be identical, nor that
the inputs be of the same nature;
- does not require a memory bank, nor contrastive samples, nor a large batch size
- does not require batch-wise nor feature-wise normalization;
- does not require vector quantization nor a predictor module.
Related work
Contrastive Learning, Clustering methods, Distillation methods, Information maximization methods 에
대해서 언급하고 있다.
VICReg : Detailed Description
VICReg는 joint embedding 기반 architecture입니다. 여기서 Encoder 2가지 역할을 합니다.
two representations 차이점의 정보를 제거합니다. (invariance term으로 해석 가능)
nonlinear로 확장합니다. Embedding된 vector간의 역상관성을 가져올 수 있습니다.

이후 위의 3가지를 진행합니다.
Method


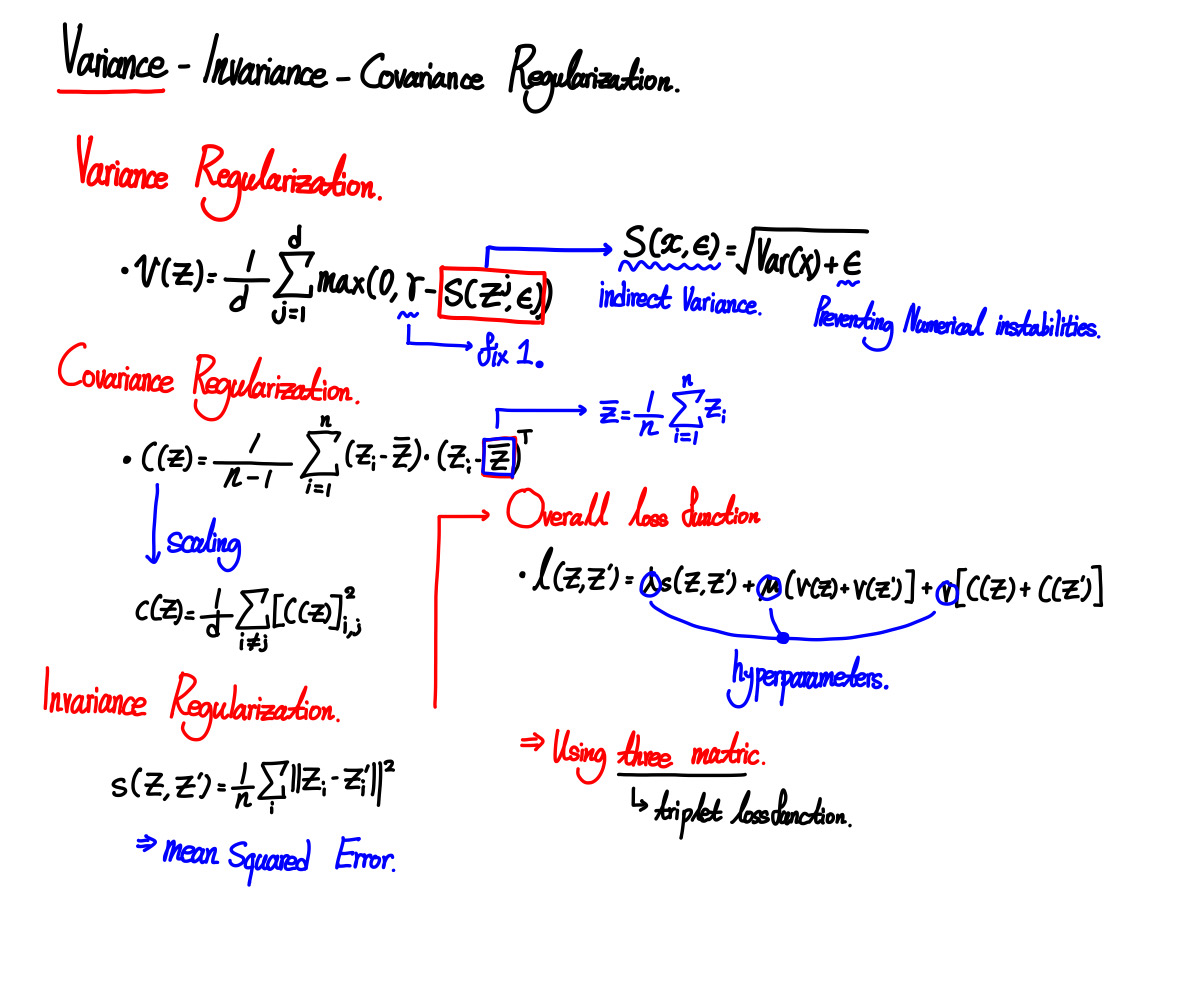
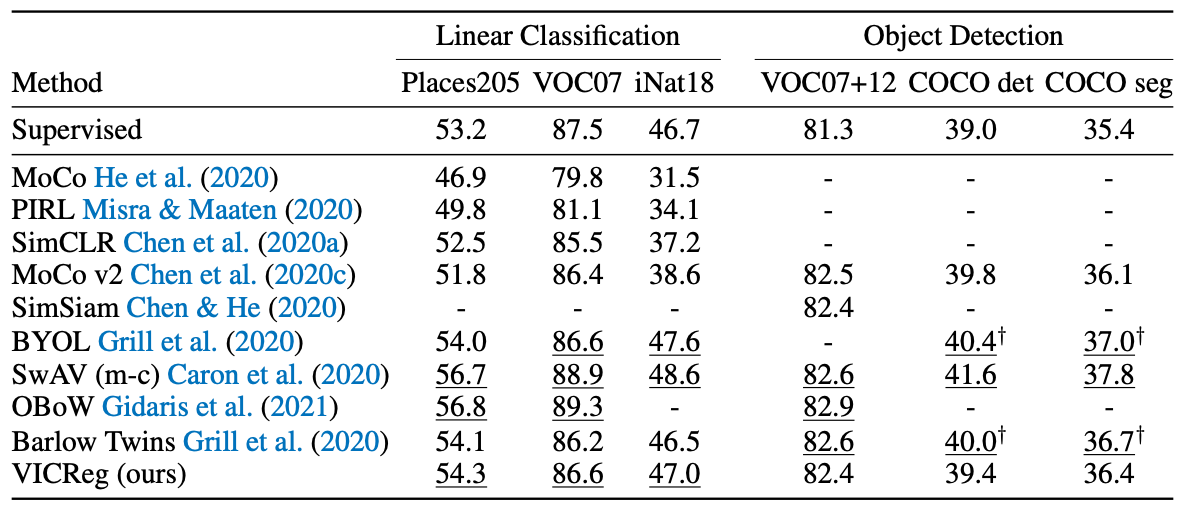
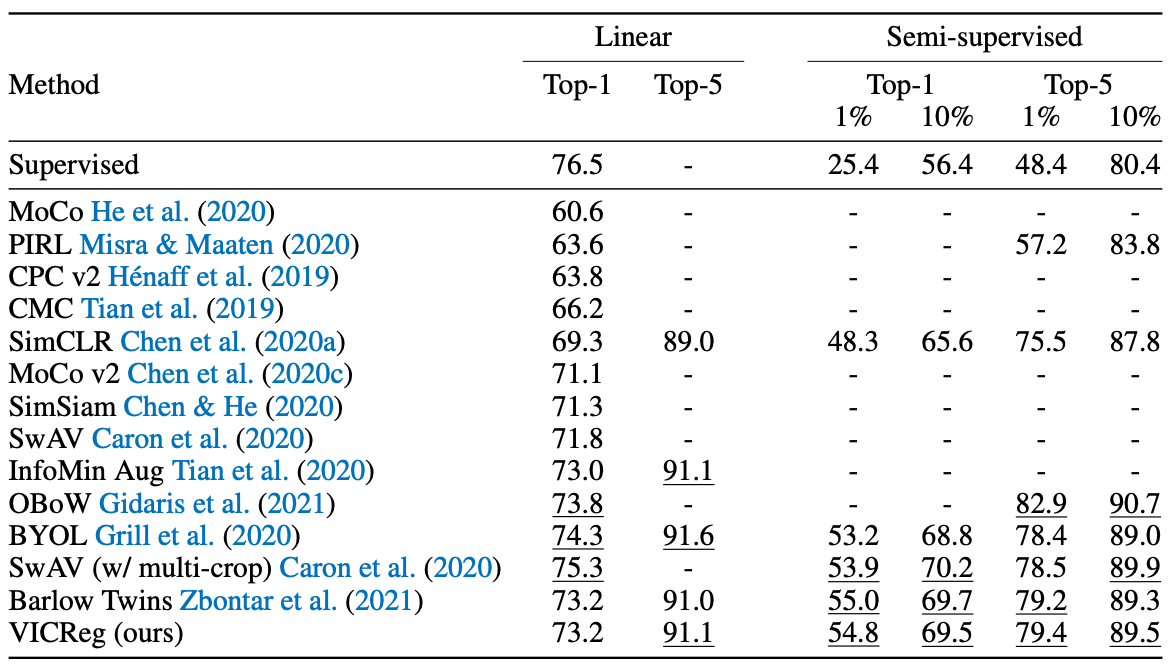
Experiments
Implement
x = self.projector(self.backbone(x))
y = self.projector(self.backbone(y))
repr_loss = F.mse_loss(x, y)
x = torch.cat(FullGatherLayer.apply(x), dim=0)
y = torch.cat(FullGatherLayer.apply(y), dim=0)
x = x - x.mean(dim=0)
y = y - y.mean(dim=0)
std_x = torch.sqrt(x.var(dim=0) + 0.0001)
std_y = torch.sqrt(y.var(dim=0) + 0.0001)
std_loss = torch.mean(F.relu(1 - std_x)) / 2 + torch.mean(F.relu(1 - std_y)) / 2
cov_x = (x.T @ x) / (self.args.batch_size - 1)
cov_y = (y.T @ y) / (self.args.batch_size - 1)
cov_loss = off_diagonal(cov_x).pow_(2).sum().div( self.num_features)
+ off_diagonal(cov_y).pow_(2).sum().div(self.num_features)
loss = ( self.args.sim_coeff * repr_loss + self.args.std_coeff * std_loss
+ self.args.cov_coeff * cov_loss)
return loss
class FullGatherLayer(torch.autograd.Function):
"""
Gather tensors from all process and support backward propagation
for the gradients across processes.
"""
@staticmethod
def forward(ctx, x):
output = [torch.zeros_like(x) for _ in range(dist.get_world_size())]
dist.all_gather(output, x)
return tuple(output)
@staticmethod
def backward(ctx, *grads):
all_gradients = torch.stack(grads)
dist.all_reduce(all_gradients)
return all_gradients[dist.get_rank()]Conclusion
본 논문은 triplet based VICReg를 설명합니다. VICReg는 많은 downstreams에서 SOTA를 달성하였습니다. (그러기엔...?)
분산 및 표준 편차에 접근한다는 면에서는 참신한 것 같아, accept된 것 같습니다..
Reference
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
Recent self-supervised methods for image representation learning are based on maximizing the agreement between embedding vectors from different views of the same image. A trivial solution is obtained when the encoder outputs constant vectors. This collapse
arxiv.org



