
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- pytorch
- math
- CV
- Torch
- clean code
- 딥러닝
- Depth estimation
- algorithm
- dl
- PRML
- Vision
- Python
- nerf
- GAN
- FGVC
- ML
- REACT
- Front
- 알고리즘
- 3d
- nlp
- cs
- computervision
- Meta Learning
- SSL
- web
- 머신러닝
- 자료구조
- FineGrained
- classification
- Today
- Total
KalelPark's LAB
[논문 리뷰] Masked Autoencoders Are Scalable Vision Learners 본문
[논문 리뷰] Masked Autoencoders Are Scalable Vision Learners
kalelpark 2023. 3. 14. 21:08
Abstract
본 논문에서는 Self-supervised Learning으로 확장가능한 masked autoencoder를 소개합니다. input 이미지를 무작위로 patch로 분할 한 후, 몇 개는 정보를 잃게 한후, 다시 생성하도록 학습하는 방식입니다.
주된 기여로는 2가지가 존재합니다.
1. Using the Encoder Decoder structure, and reconsturcture msising patches in decoder.
(Encode, Decoder 구조를 사용합니다.)
2. we mask high propotion for self-supervised learning task.
(상당히 많은 부분 75%를 missing patches로 활용합니다.)
Introduction
GPT, BERT들은 각각의 위치를 masking 한후, masking된 곳을 맞추는 방식으로 학습을 합니다. 본 논문에서 소개하는 방식은
Denosing AutoEncoder와 유사합니다. BERT와 GPT에서 large lanugage 모델이 masked 방법을 사용하는 과정에서,
본 논문의 저자는 Vision 과 NLP에서 autoencoding의 차이는 무엇인가에 관해서, 물음을 던집니다.
본 논문에서는 몇몇의 관점을 제시합니다.
1. 기존 방법은 Vision에서는 CNN을 사용하였고, NLP에서는 Transformer를 사용하였으므로, 꽤 격차가 있었지만,
ViT가 출시된 토대로, Vision과 NLP의 격차가 붕괴되었음을 확인할 수 있었습니다.
2. NLP와 Vision에서의 정보의 밀집량 차이다.
NLP에서는 단어가 몇몇 없으면, 정교한 문장 이해를 통해서, 단어를 맞추도록 학습하는 것이 가능합니다.
이에 반하여, 이미지는 주변의 정보만으로 정보를 복구하므로, little understanding information만 있어도, 충분합니다.
그러므로, 이러한 문제를 극복하기 위해, 우리는 random patch를 높은 비율로 high portion으로 주는 것이다.
이러한 방법은 low-level image statistics를 넘어 상당히 이미지에 대한 높은 이해를 만들 수 있습니다.
(NLP의 setence information과 유사합니다.)
3. NLP의 missing word information은 상당한 semantic이 존재하지만, image의 경우 lower information을 갖게 된다.
그러므로, Image에도 high semantic information을 주기 위해서, decoder를 design을 합니다.
이러한 3가지 분석을 통해서, 우리는 단순하고 효율적이며, 마지막으로 Self-Supervised learning으로 확장 가능한
masked AutoEncoder(MAE)를 소개합니다.

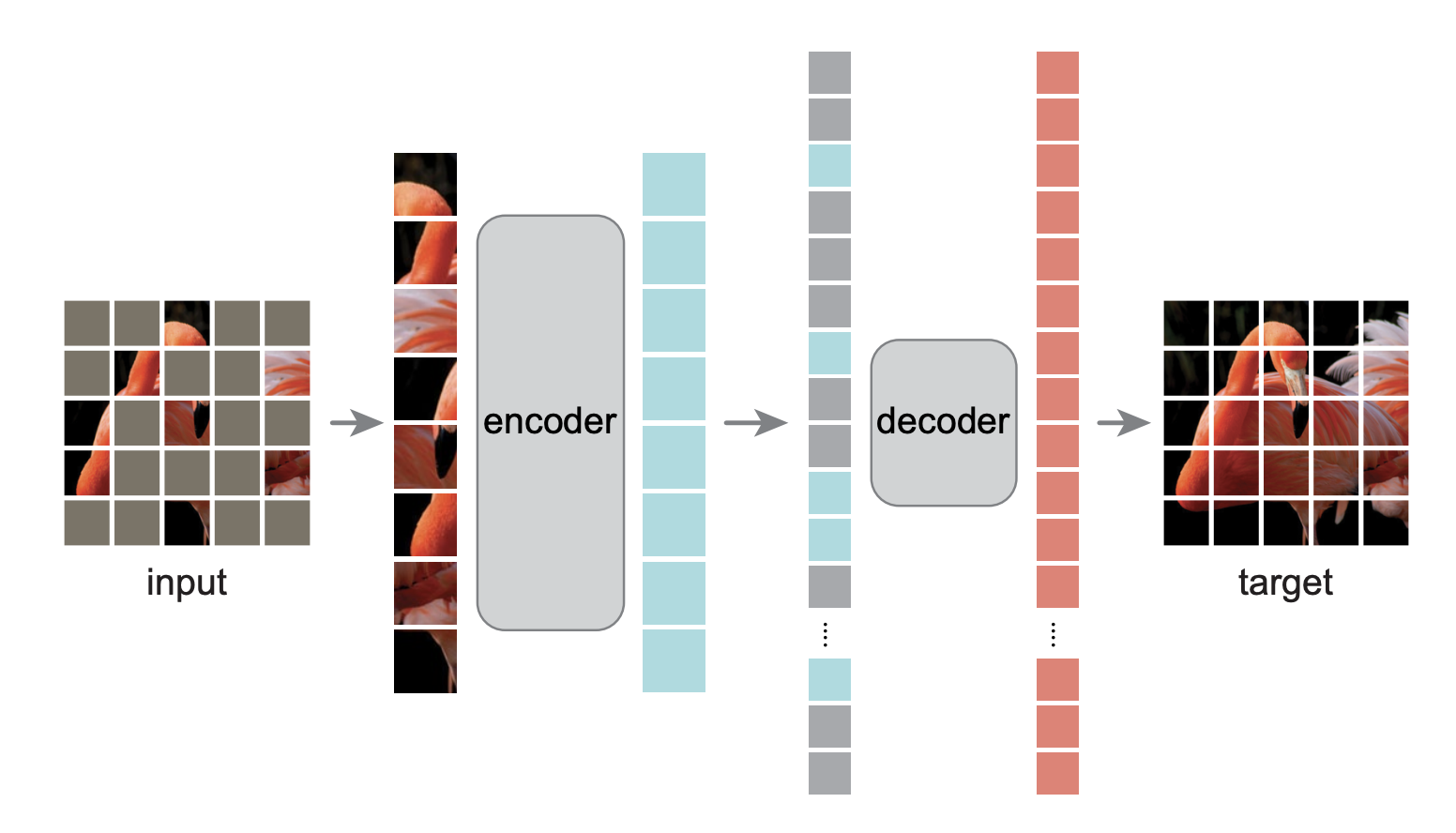
* 아래의 경우와 동일하다고 볼 수 있습니다. (학습하는 이미지가 맨 좌측이며, 생성된 이미지가 가운데, 원본 이미지가 맨 우측이다.)

Related work
Masked image encoding
masking에 의해, missing information을 reconstructure하는 과정에서 학습하는 방식은 Denosing AutoEncoder(DAE)로부터 시작됨. 이후, ViT 및 BeiTd에서 masked patch에 대하여 언급하며, SSL로의 확장 가능성을 언급함.
Approach
기존 방법론과 다르게 Encoder와 Decoder는 asymmetric design을 활용하고, Encoder에 의해 생성된 latent representation vector는 lightweight decoder를 통하여, full image를 형성
Masked AutoEncoder
기존, ViT와 같은 모델을 사용하되, masking되지 않은 이미지만을 사용하여 학습을 진행하기에, 기존 Transformer에 비해1 - portion 만큼 작동합니다.
Masked AutoDecoder
Encoder와 다르게, masked 데이터를 각각 positioning 하여, 학습에 활용합니다. 그러므로, decoder는 encoder와 다르게 independent 하게 생성하는 것이 가능하며, flexible하게 사용이 가능합니다. 또한 Lightweight이므로, 상당히 빠르다는 것을 논문에서는 언급합니다. (loss로는 pixel by mse를 사용합니다.)
Implementation
MAE의 장점으로는, any specialized sparse operation가 필요하지 않으며, inference time 또한 상당히 빠르다는 것입니다.
Image의 masking한 부분을 list에 저장하여, masking안된 부분만 encoder를 통해서 학습을 시킵니다. 이후, decoder에서는 masking된 부분을 가져와 latent vector와 같이 학습시키는 asymetric architecture을 활용합니다.
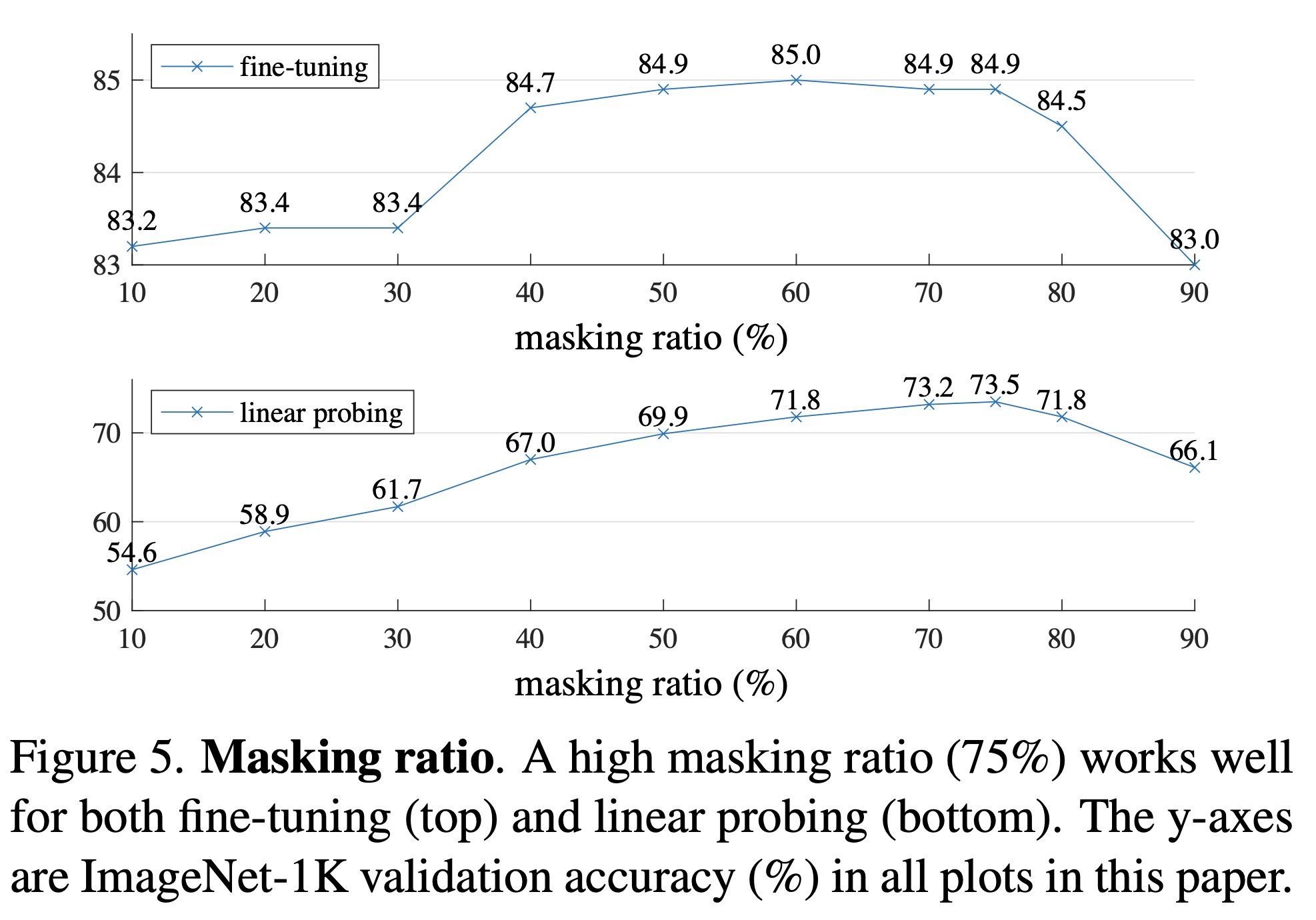
Masking ratio에 따른 성능 차이, 75% 일때가 성능이 가장 좋음을 보여줍니다.
Ablaltion Study


Discussion and Conclusion
단순한 알고리즘 및 방법론은 확장 가능하다. 본 논문은 NLP의 BERT로부터 영감을 받아, 창작하였습니다. pre-training은 Supervised domain에서 널리 사용되고 있습니다. NLP와 마찬가지로, Vision에서도, Self-supervised Learning의 대세가 시작될 수 있음을 또한 보여줍니다.
향후 계획

추후 코드 리뷰로 돌아보도록 하겠습니다..!
Reference
Masked Autoencoders Are Scalable Vision Learners
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we
arxiv.org



