
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- ML
- Depth estimation
- 딥러닝
- SSL
- Torch
- 자료구조
- classification
- pytorch
- clean code
- nlp
- PRML
- computervision
- 알고리즘
- Vision
- nerf
- FGVC
- Front
- dl
- FineGrained
- Python
- REACT
- cs
- CV
- math
- 3d
- algorithm
- web
- 머신러닝
- GAN
- Meta Learning
- Today
- Total
KalelPark's LAB
[ 논문 리뷰 ] MetaFormer : A Unified Meta Framework for Fine-Grained Recognition 본문
[ 논문 리뷰 ] MetaFormer : A Unified Meta Framework for Fine-Grained Recognition
kalelpark 2023. 1. 13. 10:44
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/Awesome-ComputerVision
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com
Abstract
Fine Grained Classification은 여러 하위 범주에 속하는 객체를 인식하는 것을 목표로 해야합니다.
최근에는 Meta-information은 보통 Image내에 속하는 것으로 알려져 있습니다.
이러한 정보들은 우리에게 질문을 던집니다.
- 통합되고, 간단한 프레임워크를 사용하여 다양한 메타 정보를 활용하여 세분화된 식별을 하는 것이 가능합니까?
이러한 문제를 관하여 답을 하기위해, 세분화된 시각적 분류를 위한 Meta-framework를 제시합니다.
MetaFormer는 Vision과 다양한 Meta information을 통합적으로 다루기 위해 효율적인 FrameWork를 제시합니다.
Meta Former는 iNaturalist2017 및iNaturalist2018 Dataset에 관하여, Vision information만을 활용하여,
Sota를 달성합니다.
Information
본 연구에서, Fine-grained Visual Classification을 위한 통합된 Meta-Framework를 제시합니다. MetaFormer는 추가의 구조
를 사용하지 않고, Visual information과 meta-information을 통합하고, Transformer를 적용합니다.
추가로, Metaformer는 fine-grained에서 필수적이라고 믿습니다.
그리고, MetaFormer는 넓게 다양한 Task에서 사용될 수 있음을 시사합니다.
추가로, Meta Data는 시각적으로 분류하기 어려운 데이터에 관해서, 신호와 같은 역할을 하므로, 상당한 도움이 됩니다.
하지만, Vision Trnasformer를 적용한다면, 서로 다른 특징들이 통합되면, 모델의 성능을 손상시키는지에 관해서는
여전히 불명확합니다.
Contribute
- Visual Appearance와 다양한 Meta information을 통합하기 위한 Meta Framework를 제안합니다.
- 본 연구에서는, global feature에 의한 강력한 FGVC모델을 설명합니다.
Method
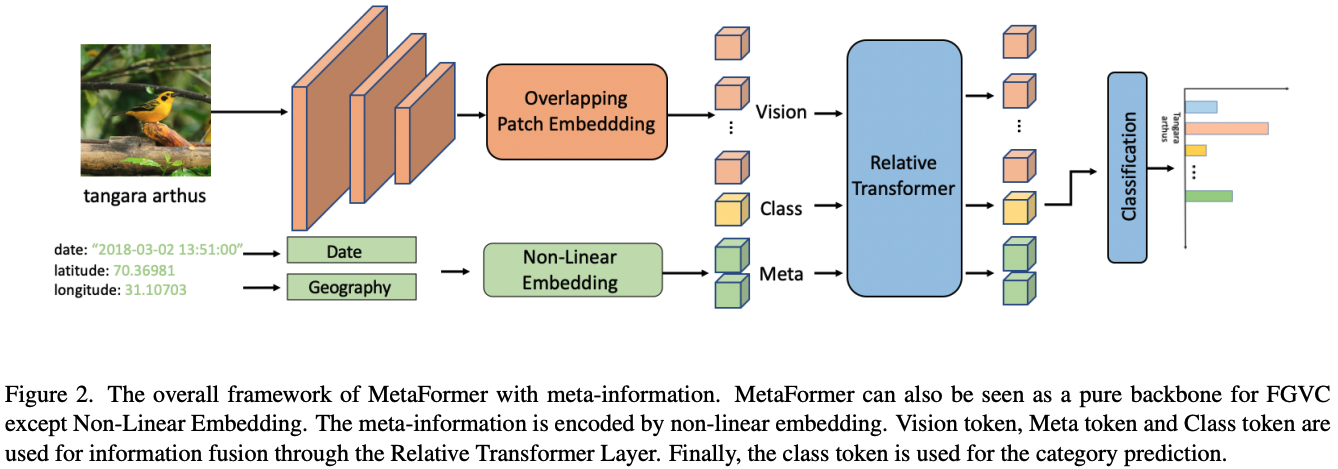
- Hybrid Framework
- Hybrid FrameWork는 Vision information을 eocoding하기 위해 사용됨
different scale을 학습하기 위해, Input size를 변환합니다. 또한, 아래의 Table과 같이, layer를 계속해서 변환합니다.

- Relative Transformer Layer

- Overlapping Patch Embedding
- Feature Map을 Tokenizer하기 위해, Overlapping Patch Embedding을 사용합니다. 또한, 복잡한 비용을 감소시키기 위해서,
Downsampling을 사용합니다. 이러한 구현을 위해, ZeroPadding을 사용하여, Overlapping을 사용합니다.
Experiments
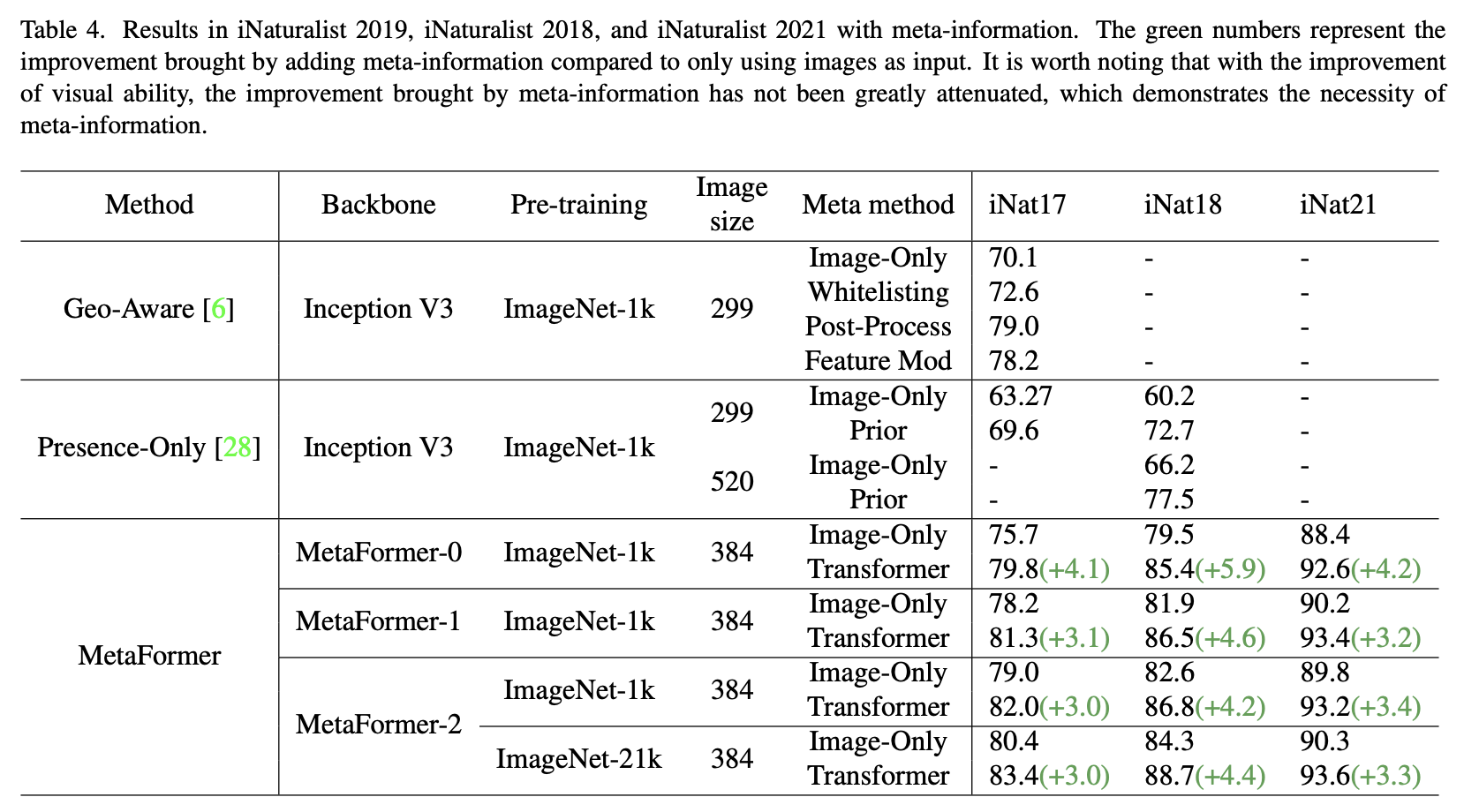
Conclusion
- 본 연구에서는, meta-information과 Fine grained Visual Classification과 통합한 방법을 제한합니다.
Reference
https://arxiv.org/abs/2111.11418
MetaFormer Is Actually What You Need for Vision
Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in Transformers can be replaced by spa
arxiv.org
https://arxiv.org/abs/2203.02751
MetaFormer: A Unified Meta Framework for Fine-Grained Recognition
Fine-Grained Visual Classification(FGVC) is the task that requires recognizing the objects belonging to multiple subordinate categories of a super-category. Recent state-of-the-art methods usually design sophisticated learning pipelines to tackle this task
arxiv.org
'Data Science > Fine Grained' 카테고리의 다른 글
| [논문 리뷰] ProtoTree for Fine Grained Image Recognition (0) | 2023.01.01 |
|---|---|
| [논문 리뷰] TransFG [2021] (0) | 2022.12.10 |
| [논문 리뷰] PIM(Plug in Module) [ 2022 ] (0) | 2022.12.06 |
| [논문 리뷰] Counterfactual Attention Learning [2021] (0) | 2022.12.05 |
| [논문 리뷰] Look into Object [2020] (0) | 2022.12.03 |



