
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 딥러닝
- nlp
- CV
- 자료구조
- computervision
- dl
- nerf
- math
- 3d
- cs
- web
- pytorch
- GAN
- Vision
- clean code
- Meta Learning
- FineGrained
- Depth estimation
- Python
- SSL
- 알고리즘
- REACT
- 머신러닝
- classification
- algorithm
- PRML
- ML
- Front
- FGVC
- Torch
- Today
- Total
KalelPark's LAB
[논문 리뷰] PIM(Plug in Module) [ 2022 ] 본문

GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/AI_PAPER
GitHub - kalelpark/AI_PAPER: Machine Learning & Deep Learning AI PAPER
Machine Learning & Deep Learning AI PAPER. Contribute to kalelpark/AI_PAPER development by creating an account on GitHub.
github.com
Abstract
Fine Grained는 일반적인 Classification에 비하여, 상당히 어려운 task입니다. 이전의 연구에서는, end-to-end train이 안되었으며, multi-stage architecture가 요구 되었습니다.
본 논문에서는 CNN 기반의 module과 Transformer 모듈에 discriminativce regions을 제공하는 것이 가능한 Module을 제안합니다. Plugin module은 pixel-level feature map을 출력하며, fine-grained를 위해 강화된 filter를 혼합합니다.
Introduction
FGVC관련하여, 논문에서 소개하고 있다. feature map과 Object 위치사이에서의 관계를 이해하기 위해서, FGVC 기법과 Object Detection 기법간의 연구를 진행합니다.
Detection 기법들은 location 내에 풍부한 feature map을 가지고 있습니다.
하지만 이러한 방법론들은 사람들이 만든 annotation이 필요합니다.
그러므로, 우리는 Weakly Supervised Object Detection(WSOD) 방법을 활용해야 합니다. Weakly Supervised Object Detection(WSOD)는 Object의 location이 반영된 feature map입니다.
그리고, 이러한 feature map을 활용하여, Weakly Supervised Multi-stage architecture와 loss function을 통하여 경계 상자 예측하는 것이 가능합니다.
다양한 크기의 feature를 탐지하기 위해, FPN을 추가하고, 다양한 scale의 feature들을 섞습니다. 이러한 접근법은 local represntation의 quality를 개선하는 것이 가능합니다.
Plugin Module은 3가지의 Operation으로 구성되어 있습니다.
- division
- Competition
- combination

다른 클래스로 레이블로 지정된 training data가 역방향 전파 중에 샘플 공간에 수렴하기에 상당히 어렵기 때문이다. 이러한 방법은 Background에 대한 정보를 제거하고, Object에 대한 정보만을 가져가게 합니다.
Contributes
- 다양한 모델에 적용하는 것이 가능한 plug-in Network를 소개합니다. 이러한 Network는 Background의 segmentation과 feature fusion techniques를 통합합니다. FGVC에서는 이러한 방법을 활용하면, Accuracy를 향상시키는 것이 가능합니다.
- 이러한 방법을 활용하였을 때, SOTA를 달성하였습니다.
Plug-in-Module for FGVC
ResNet, EfficientNet등 여러 모델에 자유롭게 엮는 것이 가능한 plug-in module을 제안합니다. 우리의 전반적인 design은 feature map에서 각각의 pixel을 independence feature로 treat하는 것이다.
이러한 feature들을 분류하고, 구별을 위한 classification ability 능력을 향상시킵니다.
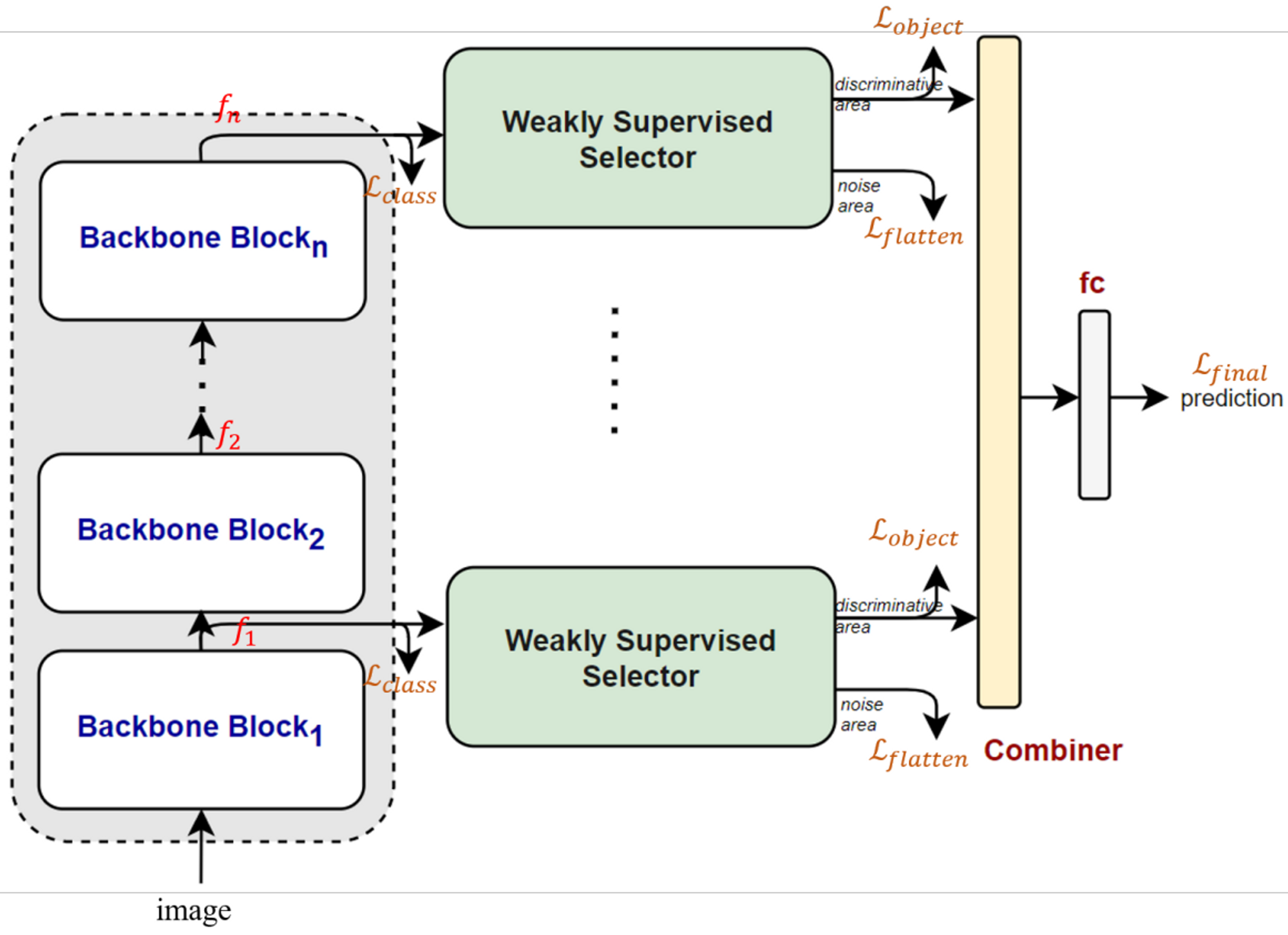
Image를 Network내에 Input으로 넣었을 때, 각각의 block에 의한 feature map의 Output은 Weakly Supervised Selector의 Input으로 활용됩니다.
이후, Weakly Supervised Selector에 의한 Output과 FeatureMap을 결합하여, 예측된 결과를 초래하는 것이 가능하게 합니다.
Module Design
FGVC 기법은 area를 잘라내고, secondary training process동안 attention을 증가시킵니다. 반면, WSOD frameworks는 Multiple instance Learning(MIL)을 활용합니다.
두 가지 약간의 차이가 존재하지만, pixel-level features는 classification task에서 상당히 중요하다는 것을 나타냅니다. softmax 이후에, 여측된 결과의 확률값이 높을 때, feature는 유용한 feature로 여겨질 수 있습니다. 그리고 subsequent fusion을 위해, 반환됩니다.
이러한 feature map은 weakly supervised selector에 들어갑니다. 그리고 각각의 feature points는 linear classifier에 의하여, 분류됩니다.
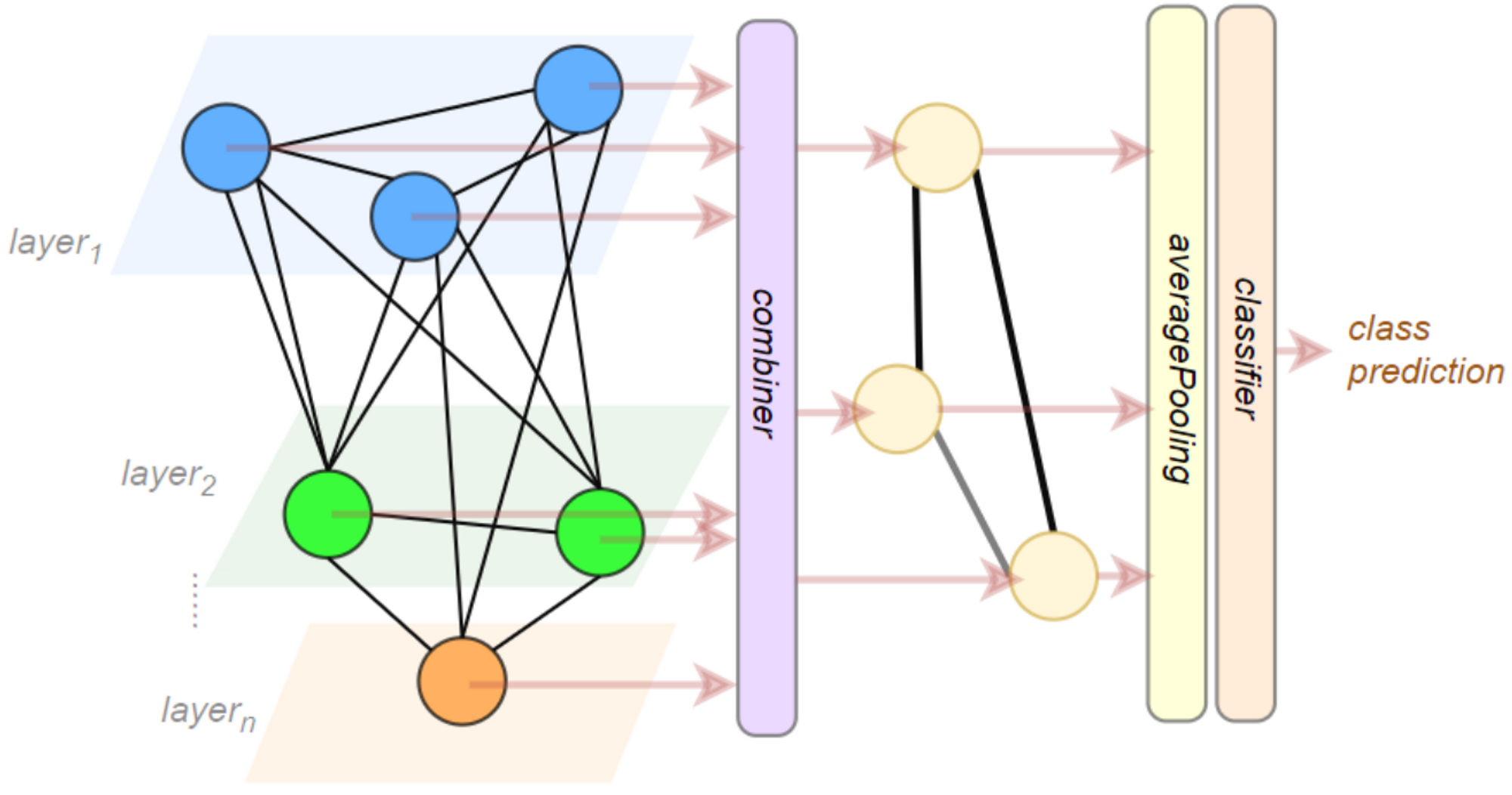
difference scales의 feature Map들이 선택되어 활용됩니다. different scales feature map은 위의 이미지에서 각각의 다른 색상을 나타내고 있습니다. feature들은 Combiner를 통하여, 통합됩니다.
이후, fused features를 통하여, 최종적으로 recognition을 진행합니다. 본 모델은 2가지로 구현되어 있습니다.
- 전체의 Image를 표현하는 global features안에서 선택된 local features들이 recombination됩니다.
- second architecture은 graph convolution으로 구현됩니다. pooling layer를 통하여, 몇몇의 super nodes들로 feature points들이 통합됩니다. 이후 super nodes의 feature들은 average됩니다. 이후, 완벽한 예측을 위해서, linear classification이 활용됩니다.
이러한 방식의 장점은 각각의 feature들은 more efficiently하게 활용됩니다. 추가로, small regions의 feature를 효율적으로 추출하기 위해서, 우리는 FPM을 backbone network에 추가합니다.
Backward Propagation
각각의 block으로부터, cross entropy를 계산하기 위해, block으로부터 추출된 값들에 관하여, loss를 측정합니다. 또한 Mask를 활용하여, strong discriminative의 feature map을 추출합니다.
이후, 추출된 feature를 활용하여, classification에 활용하고, 이후 loss로 활용합니다. 또한, Mask를 활용하여, loss로 활용하고, 이것을 crossentropy로 활용합니다.
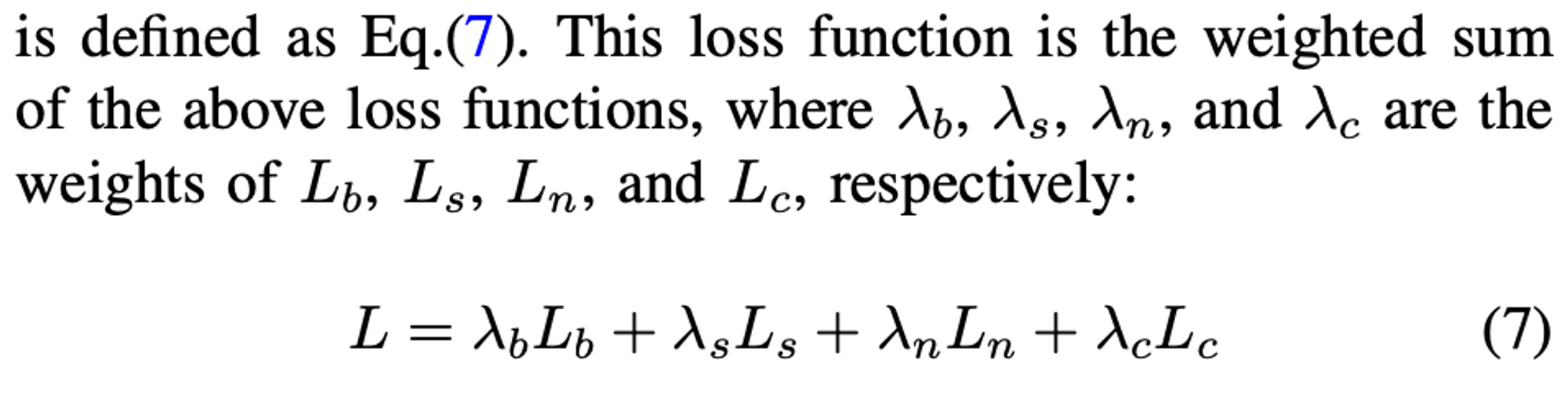
논문을 보면, 더 자세하지만, 각각 순서대로 말하자면, block을 활용한 classification loss, mask를 활용한 loss, mask를 제외한 것을 활용한 loss, 전체 feature를 합한 loss를 총 합산에서 loss로 활용합니다.
본 논문에서는 쉽고 단순한 방식으로 local feature를 활용하여, class를 예측합니다. 이러한 방법은, 지역 배경 또는 다른 classes의 유사한 부분의 예측 값을 구별하게 어렵게 합니다.
최종적으로, 선택된 features는 global feature안에서 혼합됩니다. 이러한 방법은 다양한 Model에 적용하는 것이 가능하며, end-to-end인, One - Stag training 가능합니다.
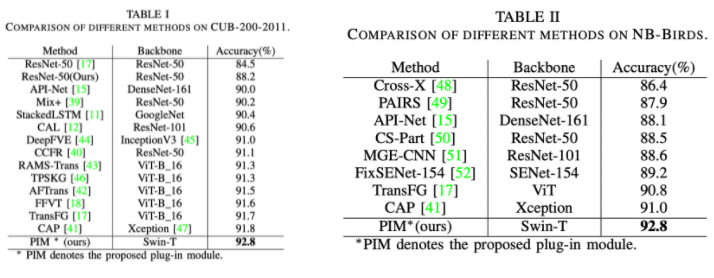
Experiments
Reference
A Novel Plug-in Module for Fine-Grained Visual Classification
A Novel Plug-in Module for Fine-Grained Visual Classification
Visual classification can be divided into coarse-grained and fine-grained classification. Coarse-grained classification represents categories with a large degree of dissimilarity, such as the classification of cats and dogs, while fine-grained classificati
arxiv.org
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/AI_PAPER
GitHub - kalelpark/AI_PAPER: Machine Learning & Deep Learning AI PAPER
Machine Learning & Deep Learning AI PAPER. Contribute to kalelpark/AI_PAPER development by creating an account on GitHub.
github.com
'Data Science > Fine Grained' 카테고리의 다른 글
| [논문 리뷰] ProtoTree for Fine Grained Image Recognition (0) | 2023.01.01 |
|---|---|
| [논문 리뷰] TransFG [2021] (0) | 2022.12.10 |
| [논문 리뷰] Counterfactual Attention Learning [2021] (0) | 2022.12.05 |
| [논문 리뷰] Look into Object [2020] (0) | 2022.12.03 |
| [논문 리뷰] Progressive Multi Granularity [2020] (0) | 2022.11.30 |



