
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- dl
- cs
- ML
- Python
- CV
- nlp
- Front
- nerf
- FGVC
- REACT
- 알고리즘
- Torch
- GAN
- Vision
- Meta Learning
- math
- web
- classification
- PRML
- algorithm
- Depth estimation
- clean code
- 딥러닝
- SSL
- 3d
- pytorch
- 머신러닝
- computervision
- 자료구조
- FineGrained
- Today
- Total
KalelPark's LAB
[논문 리뷰] A critical analysis of self-supervision, or what we can learn from a single image 본문
[논문 리뷰] A critical analysis of self-supervision, or what we can learn from a single image
kalelpark 2023. 3. 30. 09:00
Abstract
본 논문은 label 없이, model을 학습하는 Self-Supervised Learning을 분석합니다.
본 논문은 3가지 method를 비교합니다. (BiGAN, RotNet, DeepCluster). 데이터가 상당히 많더라도, Supervision과 같이 학습하는 것은 불가능합니다. 1) 본 논문은 초기 layer에서는 natural images의 통계에 대한 정보를 갖는 것이 힘들다는 것을 설명하고, 2) self-supervision에서는 그러한 표현력을 Self-supervision을 통해서, 학습될 수 있다고 설명합니다. 그리고, 대규모 데이터셋을 사용하는 것 대신 합성 변환을 활용하여, low-level statistics를 포착할 수 있습니다.
Introduction
본 논문에서는 일반적인 데이터셋으로부터 얼마나 많은 정보를 추출할 수 있는지에 대해서 분석합니다. 본 논문에서는 궁극적인 물음은
"여러 정보를 학습하기 위해 Self-supervised Learning은 많은 수의 이미지에 포함된 정보를 활용할 수 있는가?"입니다.
2가지 주된 결과를 보여줍니다.
1) Self-supervision과 data augmentation을 결합할 때,
단일 이미지로부터 일반적인 모델의 few layers를 학습시키는 것이 가능합니다. 또한 이미지의 다양성과 반대되는 low-level feature를
학습할 때는 image transformation이 중요함을 발견합니다.
2) Self-supervision은 supervision에 비해서, 상당히 많은 데이터가 있음에도 학습하는데 열등함을 가집니다. 특히 우리는 self-
supervision과 single images로 여러 layer를 학습하는 것은 여러 다른 이미지를 사용하여 달성할 수 있는 성능의 2/3 만큼 달성한다
는 것을 보여줍니다.
전반적으로 우리의 결과는 SSL을 개선하지는 못하지만, 현재 방법들의 제한을 특성화하고, 남은 과제에 집중할 수 있도록 돕습니다.
Related Work
Self supervised Learning
coloraztion과 in-painting은 단점을 지니고 있습니다. SSL시에는 수정된 이미지를 학습하기 때문에, supervision에서는 수정되지 않은 이미지를 일반화하는데 상당히 어려움을 지니고 있습니다. 이후 Video와 관련된 여러 SSL에 대해서 언급을 하고 있습니다.
우리가 논문에서 사용하는 3가지 방법은 서로 각기 다른 것을 학습합니다. BiGAN은 generative adversarial로 학습을 하며, RotNet의 경우 현실적인 정보를 추출하는데 초점을 두고, DeepCluster의 경우 안정적인 표현을 학습하는 것을 목표로 합니다.
Method
Representation Learning Methods
Generative models : GAN은 generate image를 adversarial objectice를 활용하여 학습합니다. generator network는 noise sample을 image sample로 mapping합니다. BiGAN(Bidirectional Generative Adversarial Networks)은 유용한 이미지의 표현을 근사적으로 학습하도록 설계된 GAN의 확장입니다. 즉, image의 encoding과 joint inference를 통하여, 생성기의 반대로써 유용한 이미지의 표현을 학습하는 것이 목적입니다.
Rotation : 대부분의 이미지들은 인간이 올바르게 보는 정도를 지니고 있습니다. photographersms data labelling을 명시적으로 할 수 있습니다. RotNet에서는 저자들이 직립의 개념이 학습에서 필요한 이유를 설명합니다. 그러한 이유로 해당 메서드는 low-level visual information을 얻는것에 취약하지 않을 뿐만 아니라, network가 추상적인 정보또한 학습하도록 장려합니다.
Clustering : 최근의 SOTA인 DeepCluster는 data에 대해서 Pseudo labelling을 거친 후, 이러한 label들을 학습합니다. 이러한 방법은 PCA를 사용하는 접근법입니다.
Experiments
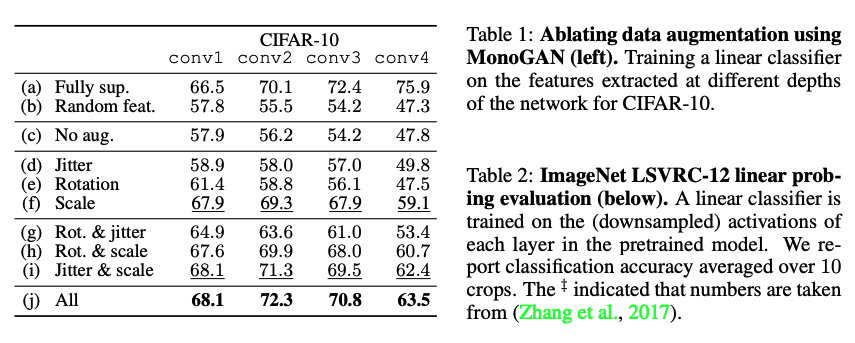
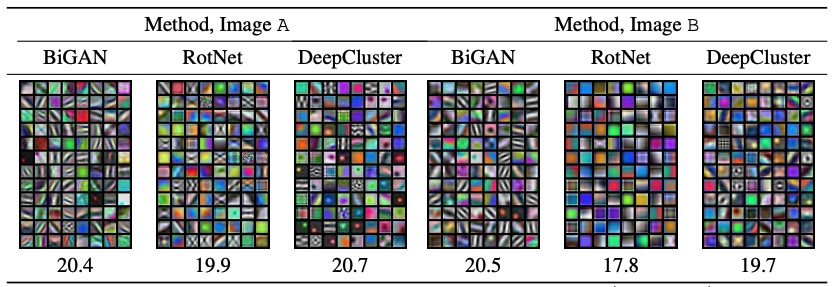
Conclusion
본 논문에서는 충분한 data agumentaiton을 사용한다면, 일반화된 feature들을 학습할 수 있다고 한다. 우리의 주된 결론은 simplest image 로부터 학습이 가능하다는 것과 deep layedr의 경우, large datasert을 사용하면, supervised와 격차가 발생합니다.



