
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Depth estimation
- Meta Learning
- pytorch
- FGVC
- 딥러닝
- math
- REACT
- nlp
- Torch
- ML
- 3d
- 머신러닝
- PRML
- CV
- Vision
- computervision
- 자료구조
- Python
- classification
- SSL
- algorithm
- clean code
- web
- 알고리즘
- dl
- FineGrained
- GAN
- nerf
- cs
- Front
- Today
- Total
KalelPark's LAB
[ 논문 리뷰 ] CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features 본문
[ 논문 리뷰 ] CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
kalelpark 2023. 2. 7. 20:24
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/Awesome-ComputerVision\
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com
Abstract
Regional dropout strategies는 계속해서 성능을 향상시켜왔습니다. MixUp, Cutout순으로 발전해왔으며, 이후 CutMix가 탄생하였습니다. 이전의 방법론들은 정보를 잃거나, 학습을 하는데 비효율적이였습니다. 본 논문에서는 CutMix Augmentation 전략을 도입함으로써, 모든 pixel을 training하는 것이 가능하며, 효율적으로 regional dropout하는 것이 가능합니다. CutMix는 다양한 task에서 높은 성능향상을 야기합니다.
Introduction
본 논문에서는 어떻게 deleted regions을 최대화하면서, regional dropout을 활용하면서 일반화와 지역화를 가져올 수 있는지 설명합니다. 이미지의 부분에서 제거된 영역을 다른 이미지로 영역을 채웁니다. CutMix를 활용함으로써 다른 class와 차별적이지 않은 부분까지 학습을 하게 됩니다. 뿐만 아니라, 모델이 객체의 일부분을 확인하는 것을 요구함으로써 더해진 patch는 localization을 향상시킵니다.
CutMix는 추가적인 비용 예산 없이도 상당한 성능향상을 기여하며, 모델의 Architecture를 변환할 필요가 없습니다.


Relation Work
Regional dropout, Synthesizing training data, Mixup, Tricks for trainin deep network를 언급합니다. Regional dropout의 경우에는 일반적인 dataset에서, 이미지 내 특징적인 부분을 제거하는 것을 설명하며, Synthesizing training data에서는, 각각의 다른 class의 data를 섞는 방법을 설명합니다. 그중 Mixup을 설명하는데 관련 논문은 하단에 링크를 추가하도록 하겠습니다. Tricks for training deep network에서는 Deep Learning 모델에서 새로운 특징을 추가하기 위해, cost를 추가하는 경우가 일반적임을 설명합니다. 하지만 CutMix의 경우에는 data level에서 학습을 하므로, no cost를 장점으로 설명합니다.
Algorithm
2개의 class가 다른 데이터를 각각 (X_{A}, Y_{A}), (X_{B}, Y_{B})라고 지칭합니다. 이후 새로운 이미지를 생성하는 생성한 이미지를
(~x, ~y)라고 합니다. M의 경우 binary mask라고 보면 됩니다. 이미지에 곱으로 활용하여, 새로운 이미지를 형성할 때 활용됩니다. 람다 값의 경우 0~1 사이인데, combination rate이라고 보면 됩니다. 0 ~ 1 사이인 uniform distribution에서 하나의 값을 활용한다고 볼 수 있습니다.

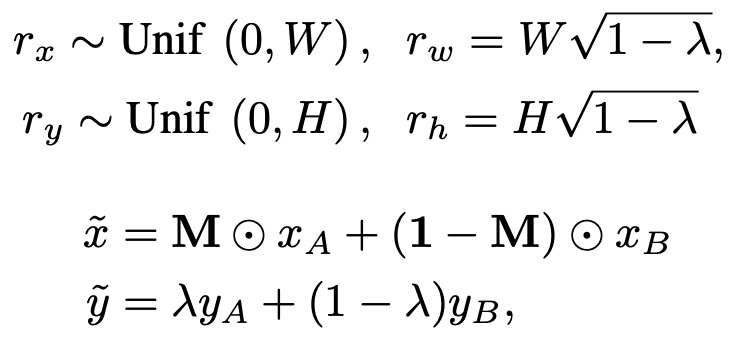
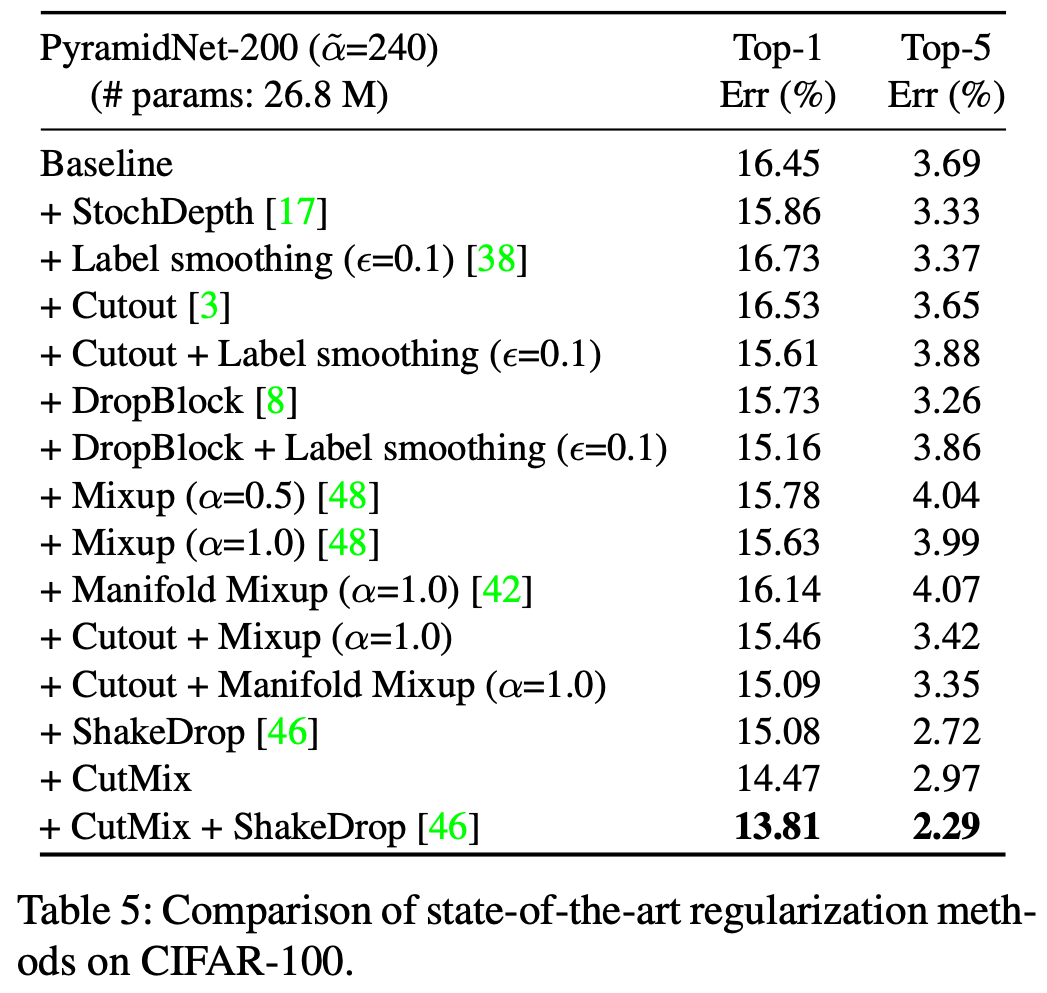
Experiments
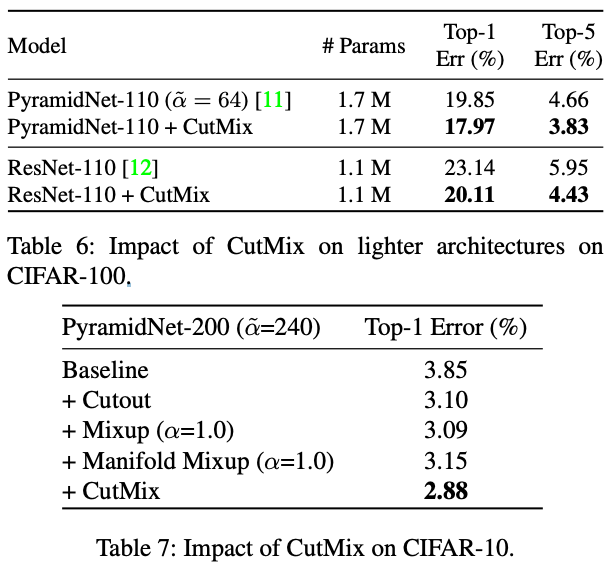
Reference
https://arxiv.org/abs/1905.04899
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
Regional dropout strategies have been proposed to enhance the performance of convolutional neural network classifiers. They have proved to be effective for guiding the model to attend on less discriminative parts of objects (e.g. leg as opposed to head of
arxiv.org
https://arxiv.org/abs/1708.04552
Improved Regularization of Convolutional Neural Networks with Cutout
Convolutional neural networks are capable of learning powerful representational spaces, which are necessary for tackling complex learning tasks. However, due to the model capacity required to capture such representations, they are often susceptible to over
arxiv.org
'Data Science > Augmentation' 카테고리의 다른 글
| Puzzle Mix: Exploiting Saliency and Local Statistics for Optimal Mixup (0) | 2023.03.16 |
|---|
