
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- PRML
- dl
- math
- REACT
- web
- Front
- 3d
- algorithm
- pytorch
- GAN
- CV
- 알고리즘
- SSL
- ML
- nlp
- Python
- 딥러닝
- FineGrained
- FGVC
- 자료구조
- Vision
- cs
- computervision
- clean code
- nerf
- Torch
- 머신러닝
- Depth estimation
- classification
- Meta Learning
- Today
- Total
KalelPark's LAB
Puzzle Mix: Exploiting Saliency and Local Statistics for Optimal Mixup 본문
Puzzle Mix: Exploiting Saliency and Local Statistics for Optimal Mixup
kalelpark 2023. 3. 16. 16:39
Abstract
기존 방법론들은 training distribution에 적합한 성능을 달성하였지만, 학습된 네트워크는 과적합되기 쉽고, 적대적 공격에 취약합니다.
이러한 문제를 해결하기 위해, Mixed 기반 Augmentation이 대두가 되지만, 이것은 이전에 인지하지 못한 객체를 인지하는데 초점을 두어, 모델에 오히려 오해의 소지를 제안할 수 있습니다.
이러한 문제를 해결하고자, PuzzleMix를 본 논문에서 제안합니다. 그러므로, 주변 환경정보를 활용하는 학습하는 방법론인 PuzzleMix를 제안합니다. 이는 optimal mixing mask와 saliency discounted optimal transport obejective 사이를 최적화하는 방식으로 문제를 해결하고자 합니다.
Introduction
딥러닝의 일반적인 학습방식은 데이터를 학습하여, 기억한후, test데이터로 평가하는 것이다. 하지만, training data distribution에서 slight shift만 있어도, model의 성능이 악화를 가져옵니다. (필요성)
결국 Data Augmentation은 데이터를 일반화하도록 하여, 성능을 향상시키는데 목적을 둡니다. (Augmentation 이유)
최근에는 여러 Mixup들이 많이 발전하고 있지만, 그러나 이러한 방법은 기본 이미지에서 모델이 학습하는 방법을 잘못 안내하기도 하고, 일반화 성능을 저하시킬 수 있는 우려가 있습니다.
이러한 문제를 해결하기 위해, 본 논문에서는 PuzzleMix를 제안합니다. Puzzlemix는 여러 통계정보를 같이 활용하여 학습하는 방법입니다. PuzzleMix의 주된 기여는 2가지가 됩니다.
1) 주어진 영역에서 2개의 이미지에서 숨길 부분을 정하고, masking을 최적화하는 방법을 발견하는 것
2) masking 된 이미지에서 중요한 특징을 최대화하기 위해 model이 최적의 부분을 학습하도록 하는 것
최적화 과정은 sliding block puzzle을 상기시키기에, 그러므로 논문에서는 PuzzleMix라고 합니다. 데이터의 통합적인 정보를 보존하기위해 local statistics기반하에 다양한 정보를 객체에서 추출하여, 최적화를 진행합니다. 제안된 방법은 masking을 하는 최적의 방법을 찾고, 효율적으로 mini-batch에서 최적화된 mixup을 생성하는 것입니다.
이러한 방법은 computation 없이, adversarial를 포함하여, 학습하는 것을 허용합니다. 그리하여, 모델은 강건해지고, 최적화를 통해서 더욱 일반화된 성능을 가져올 수 있습니다.

Related Works
Data Augmentation
해당 부분에서는, 여러가지 Augmentation을 언급하고, PuzzleMix는 위의 개선방법들을 모두 아우르고, 성능향상을 가져온다고 합니다.
Mixup
CutMix의 단점을 언급하면서, PuzzleMix는 중요한 부분도 남긴다고 말합니다.
Saliency
특징점을 얻기 위해서 기존 방법론들은 비대칭 모델을 사용하거나, pre-trained model을 사용하지 못한다는 단점이 있습니다.
우리는 이전 논문에 따라 실험을 진행하였습니다.
Optimal transport
우리는 이전의 방법론을 따라, Optimal transport를 진행합니다.
* Related Work들의 특징들을 살펴보자면, 기존 실험들에 대해서 언급하고, 본 논문의 방법론에서의 장점을 부각하고 있습니다.
Preliminaries
아래의 표는 Mixed Ratio에 따른 saliency이다. 그래프를 보면, loss와 Top-1 acc에서 Puzzle 방법이 높은 성능을 나타내고, 가장 낮은 loss를 나타낸다는 것을 알 수 있습니다.
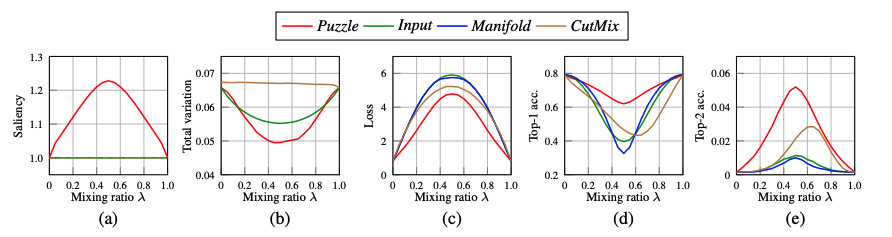
* 보다시피, 다양하게 수학적으로 해석하고 있음을 알 수 있다.
Methods
PuzzleMix는 local statistics를 유지하면서, 각각의 데이터의 유용한 정보를 최대화하는 것이 목표이다.
첫 번째로, saliency를 최대한 활용하기 위해, mixing mask를 찾는 것을 우선시 한 후, transport plans를 세웁니다.
논문을 보면 상세하게 작성되어 있으니, 참고하시기 바랍니다.


Optimal transport


Conclusion
왜 spotlight + Oral인지 알게된 논문.. 진짜 잘 작성되어 있다. 좋은 논문때문에 많은 공부 방법 및 고찰을 하게 된 계기가 된 것 같다.
단점으로는, 학습을 여러번 해야한다는 단점이 있다. 섞는 방법을 학습하고, 섞고, 어떻게 보면 SelfSupervised Learning으로 생각하게 된다. 즉, Augementation을 하기 위해 이미지를 학습하고, Augmentation된 이미지를 다시 학습하는 방법이다.
정보를 최대한 유지하면서 최대한 섞는 방법.. 이것을 Masked AutoEncoder에 적용하면, 상당한 높은 성능을 가져올 수 있을 것이라고 생각한다. CAL 논문을 다시 살펴볼 필요가 있음을 느낍니다.
Reference
Puzzle Mix: Exploiting Saliency and Local Statistics for Optimal Mixup
While deep neural networks achieve great performance on fitting the training distribution, the learned networks are prone to overfitting and are susceptible to adversarial attacks. In this regard, a number of mixup based augmentation methods have been rece
arxiv.org
'Data Science > Augmentation' 카테고리의 다른 글
| [ 논문 리뷰 ] CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features (0) | 2023.02.07 |
|---|
