
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- cs
- nlp
- clean code
- ML
- Depth estimation
- Vision
- web
- Front
- Python
- Torch
- 자료구조
- SSL
- dl
- computervision
- 딥러닝
- FGVC
- math
- Meta Learning
- REACT
- algorithm
- GAN
- nerf
- 알고리즘
- pytorch
- PRML
- CV
- 3d
- FineGrained
- 머신러닝
- classification
- Today
- Total
KalelPark's LAB
[ 논문 리뷰 ] Siamese Neural Networks for One-shot Image Recognition 본문
[ 논문 리뷰 ] Siamese Neural Networks for One-shot Image Recognition
kalelpark 2023. 1. 8. 19:25
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/Awesome-ComputerVision
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com
Abstract
기계 학습을 활용하여, 좋은 feature를 학습하는데는 Computationally expensive하고,데이터를 거의 이용하지 못하는 경우
상당한 어려움이 있습니다.
One shot Learning은 오로지 단 한장의 이미지를 학습하여, 새로운 class를 예측하는 것이 가능합니다.
본 논문에서는 입력 간의 유사성을 자연스럽게 정렬하는 독특한 구조를 가진 Siamese Neural Network를 학습하기 위한
방법에 대해서 연구합니다.
네트워크를 학습함으로써, 우리는 네트워크의 예측력을 일반화하기 위한 강력한 discriminative feature를 찾을 수 있습니다.
One shot learning은 domain-specific feature 또는 inference procedures를 개발함으로써 다뤄집니다.
결과적으로 이러한 방법들을 통합하는 시스템은, 유사한 사례에서 우수한 성능을 보여줍니다.
하지만, 다른 유형의 문제에 적용할 수 있는 강력한 솔루션을 제공하는데에는 실패합니다.
몇 가지 예로부터, 모델이 성공적으로 일반화될 수 있는 기능을 자동적으로 획득하면서,
입력 구조에 대한 가정을 제한하는 새로운 접근법을 제안합니다.
Approach
입력 구조에 대한 가정을 제한하는 새로운 접근법을 제안합니다.

본 실험에서는 Large Siamese Convoluitional Neural Network를 제안합니다.
1. Siamese는 약간의 데이터를 활용하여, 일반적인 Image feature를 예측을 하는 것이 가능합니다.
2. 일반적인 학습방식을 활용하여, 최적화하는 것이 가능합니다. 마지막으로,
3. 딥러닝 기술을 활용하여, 도메인 지식에 의존하지 않는 새로운 접근법을 제시합니다.
One-shot Image 분류 모델을 개발하기 위해서는, 이미지 쌍의 클래스를 구분할 수 있어야 합니다.
Deep Siamese Networks for Image Verfication
Siamese Network는 별 개의 입력을 받아들이지만, 상당의 Energy function에 의하여 결합되는
Neural Network로 구성되어 있습니다.
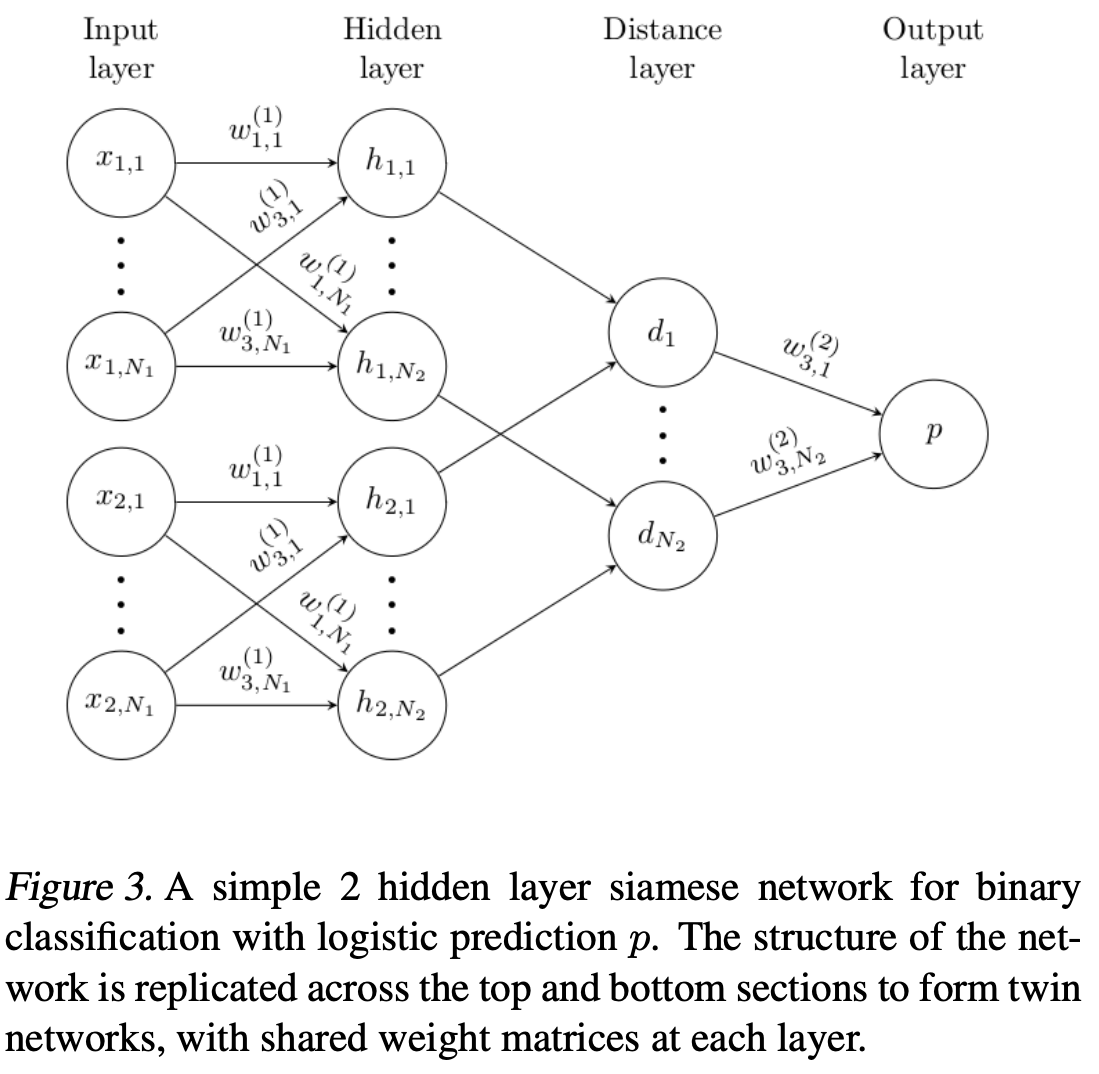
이 함수는, 각각 side 내 높은 수준의 feature 사이에서 몇몇 Metric에 의하여 계산됩니다.
각각의 네트워크가 동일한 기능을 계산하기 때문에, 매우 유사한 2개의 이미지는 각각의 네트워크에 피처 공간의
다른 위치에 매핑되지 않는다. (묶이지 않고, 별개로 학습된다면, 서로 다른 위치로 매핑되기 때문이다. )
또한, Network는 대칭적이기 때문에, twin network에 2개의 다른 이미지를 보여줄 때, top conjoining layer는
같은 metric으로 계산하여, 두 개의 이미지를 넣은 것처럼 보이지만 사실은 반대의 쌍둥이를 넣는다.
본 논문에서는 positive pairs를 활용하고, Energy줄인다. unlike pairs에 대해서는 energy를 늘리기 위한
Dual term을 가지고 있다.
Model
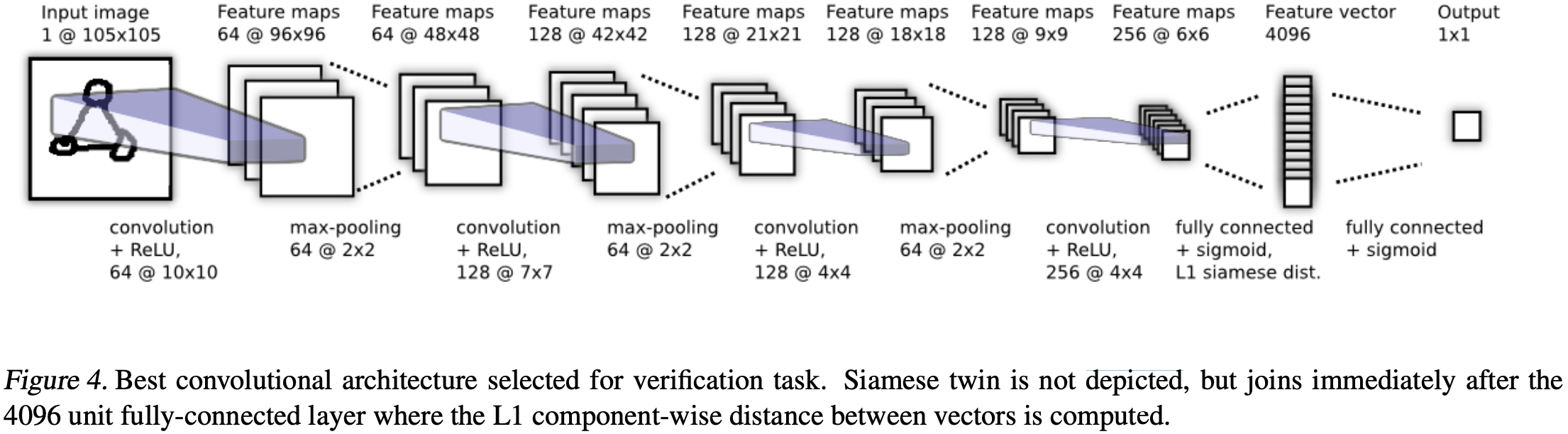
Convolutional layer들의 연속으로 이루어져 있는데, 각 layer마다, filter의 사이즈가 다르다. 뿐만 아니라, Output feature map에 ReLU activation function을 적용하고 이후 선택적으로 MaxPooling을 적용합니다.
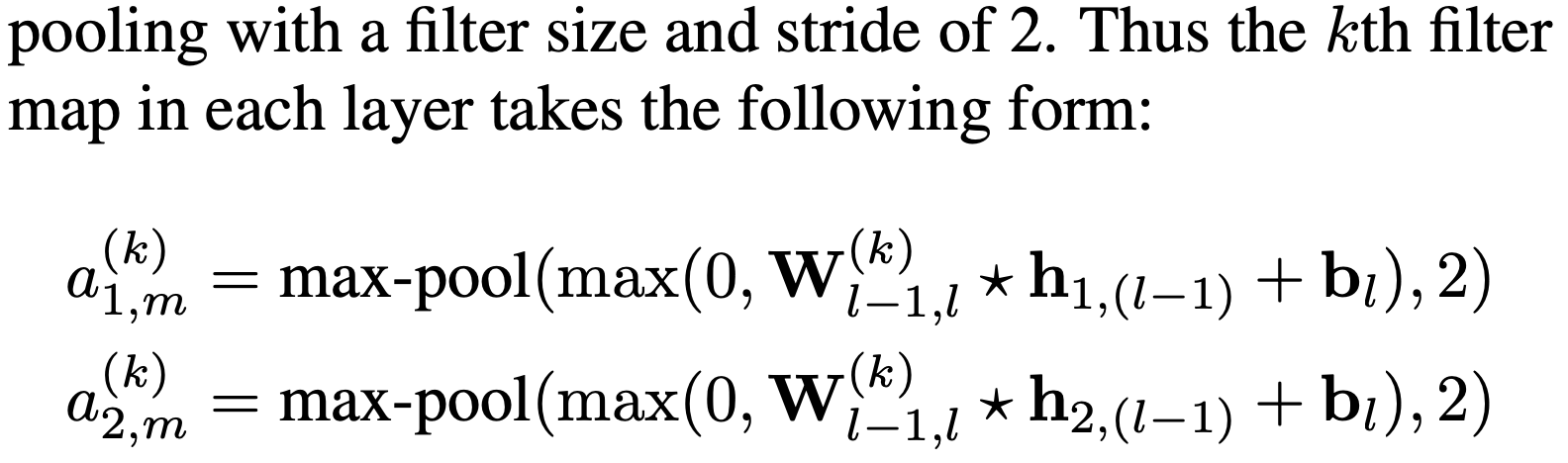
마지막, Convolution layer의 Unit들은 하나의 Vector로 계산됩니다.
fully-connected layer와 siames twin간의 distance metric을 계산하기 위한 Layer가 존재합니다.

Learning
Loss function : Cross EntropyLoss를 활용하여, Binary Classification을 진행합니다.
(동일한 것에 대해서는 1, 다른 것에 대해서는 0을 적용합니다.)

Optimization : Standard Backpropagation을 사용함으로써, Weight가 묶인 형태이기에,
twin Network간에 Gradient를 활용하는 것이 가능합니다.
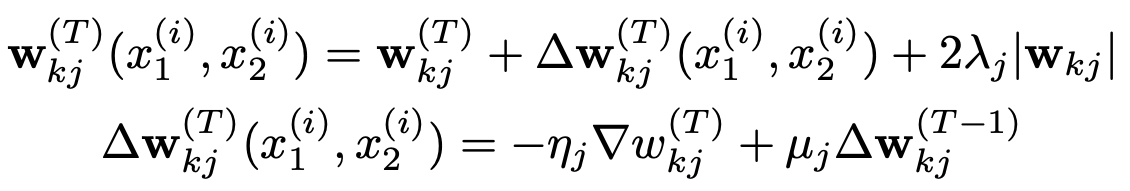
Experiments
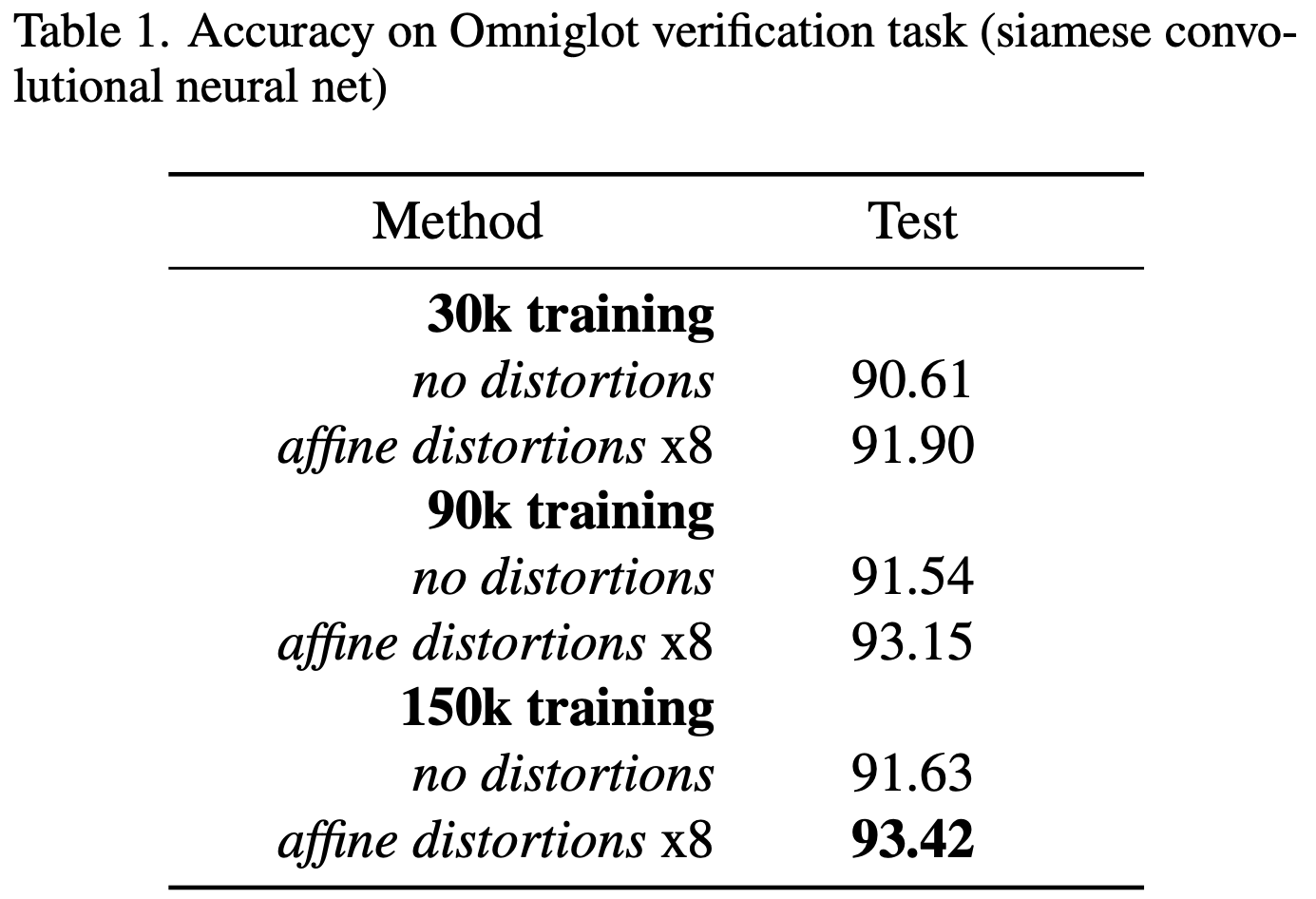
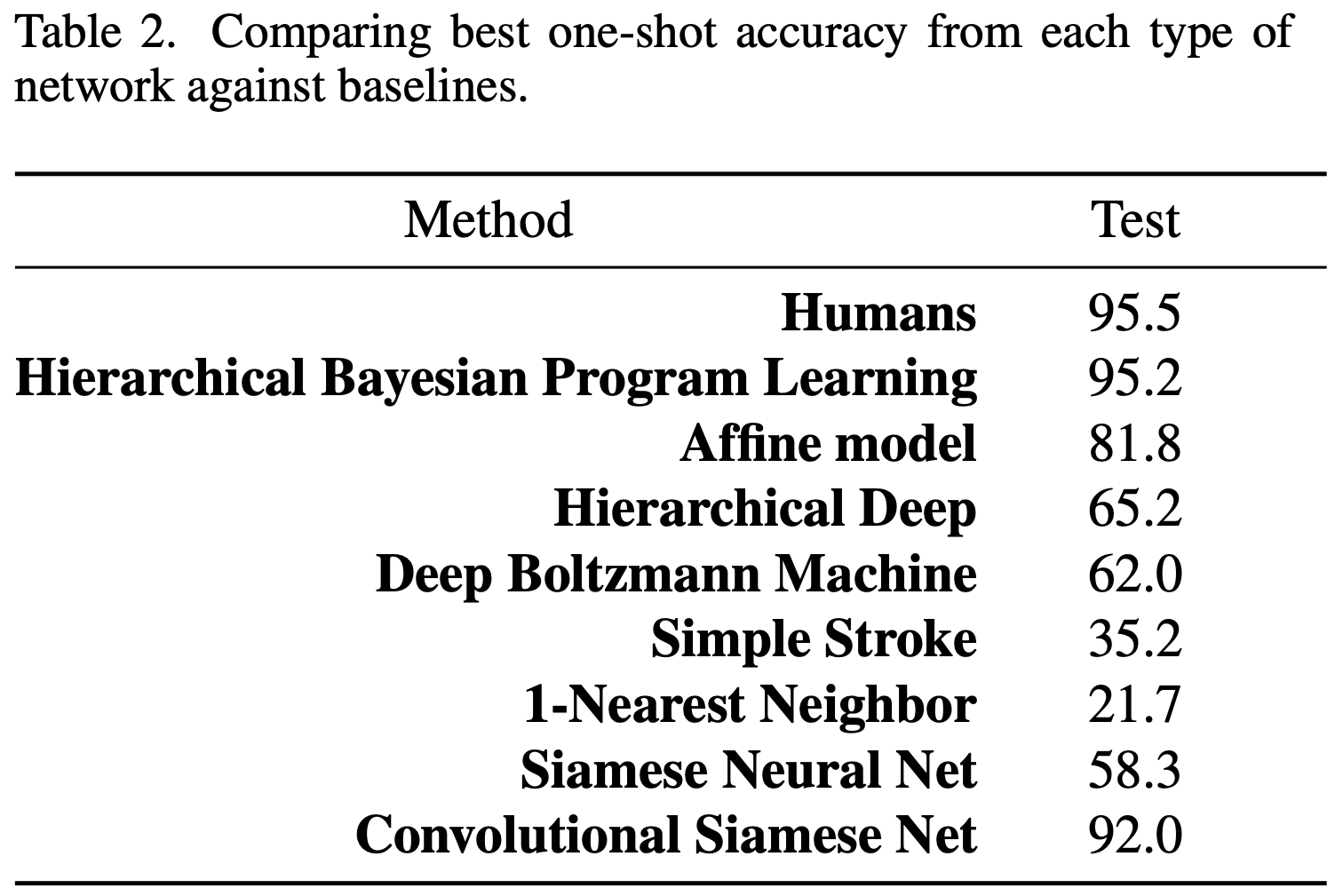
본 연구에서는 Omniglot Dataset을 사용합니다.

실험 결과
https://blog.mathpresso.com/샴-네트워크를-이용한-이미지-검색기능-만들기-f2af4f9e312a
샴 네트워크를 이용한 문제 이미지 검색기능 만들기
검색엔진 개선을 위한 이미지 검색기능 개발기
blog.mathpresso.com
'Data Science > Meta Learning' 카테고리의 다른 글
| [ 논문 리뷰 ] Prototypical Networks for Few-shot Learning (0) | 2023.01.15 |
|---|---|
| [ Meta Learning ] Meta-Learning based on Metric (2) | 2023.01.15 |
| [ 논문 리뷰 ] One-shot Learning with Memory-Augmented Neural Networks? (0) | 2022.12.29 |
| [Meta Learning] Neural Turing Machines이란? (2) | 2022.12.28 |
| [ Meta Learning ] 모델 기반 메타 러닝 이해하기 (0) | 2022.12.28 |



