
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Python
- Depth estimation
- web
- REACT
- 알고리즘
- 3d
- ML
- clean code
- cs
- CV
- FGVC
- 딥러닝
- Meta Learning
- Torch
- FineGrained
- computervision
- algorithm
- Vision
- Front
- SSL
- nerf
- classification
- nlp
- GAN
- 머신러닝
- math
- PRML
- dl
- pytorch
- 자료구조
- Today
- Total
KalelPark's LAB
[논문 리뷰] MST: Masked Self-Supervised Transformer forVisual Representation 본문
[논문 리뷰] MST: Masked Self-Supervised Transformer forVisual Representation
kalelpark 2023. 4. 4. 22:34
Abstract
기존 Transformer는 global perspective로부터 learning representation 과 high-level feature을 고려한 반면,
본 논문에서는 새로운 방법론인 Masked Self-supervised Transformer 접근법을 설명합니다.
위 방법은 local context를 포착하면서, semantic information을 보존하는 것이 가능합니다. 본 논문에서는 multi-head attention map에서 masked token strategy를 사용합니다. 이러한 방법은 이미지의 Spatial information을 보존하면서, dense prediction task에서 유용합니다.
Introduction
Yann LeCun said, 만약 지능이 cake라면, cake의 대부분은 Unsupervised learning이라고 말씀하였다. 위 문장의 의미는, 비/지도 학습은 딥러닝의 역할에 중심에 있다고 할 수 있습니다. 기존의 방법들은 Contrastive Learning을 사용함으로써, Self-supervised 와 full-supervised method간의 격차를 줄였습니다. 하지만, 대부분의 방법론들은 Global features 기반으로 image-level prediction을 하는 것은 차선책이였습니다. InfoMin은 dense prediction task로 변환하는 것이 중요하지 않음을 언급합니다.
기존 iGPT 모델에서는, 만약 token을 무작위로 마스킹을 하게되면, 성능이 저하된다는 것을 알 수 있었습니다. 랜덤 MLM은 이미지에 대해 중요한 영역의 토큰을 Masking 하면, 악영향을 끼칠 수 있으므로, ViT에 적용하기에는 적합하지 않습니다. 중요한 부분을 Masking하는 것을 회피하기 위해서, 본 논문에서는 multi-head self-attention map에서 Masking하는 방법을 제안합니다. 위 방법은 Self-supervised learning에 대한 중요한 정보에 피해주는 것없이 학습시키는 것이 가능합니다. 무엇보다도, 이러한 전략은 training time을 감소시킬 뿐만 아니라, original token을 예측하는 것만으로도, local region을 과도하게 예측하는 것을 억제할 수 있습니다.
Masked Self-supervision Transformer(MST)는 local cntext를 포착할 뿐만 아니라, global semantic information을 파악할 수 있습니다. 추가로, global image decoder는 이미지의 공간적 정보를 더 잘 파악할 수 있으며, downstream dense prediction task에서 유용하게 활용될 수 있습니다.
Contribute
- 본 논문의 주된 기여는 MST입니다. local patches masking을 guide하기 위해 self-attention의 사용합니다.
그러므로, local context semantic을 이해하고 향상시키는 것이 가능합니다.
- global image decoder에 의한 이미지의 spatial information을 효과적으로 학습하는 것이 가능합니다.
또한, 상당한 성능향상을 보여줍니다.
Method
본 논문에서는, MST를 보여줍니다. MST는 masked strategy를 사용한 이후, image reconstruction을 목표로 합니다.


The basic instance discrimination method
우리는 Mulitple views를 야기하기 위해 multi-crop에 따른 data augmentation을사용합니다. Mulit-crop에 따라 random data augmentation에 따라, 이미지에 대한 다중 뷰를 생성합니다. 위 방법은 global view를 표현하기 위한, resolution crop x1 과 x2를 사용합니다. (Sample N개의 저해상도 Crop을 생성합니다.) Encoder는 모두 Transformer로 구성되며, 이들은 서로 다른 매개 변수를 가진 동일한 Architecture를 공유합니다.


Masked token strategy
NLP로부터 영감을 받아, Random Masking Strategy를 적용합니다. Random Masking Strategy는 중요한 부분을 제거하는 경우가 있습니다. Random Masking Strategy는 이미지의 중요한 영역을 마스킹함으로써 네트워크가 객체를 인식하는데 상당히 제한적입니다.

Attention-guided mask strategy.
본 Section에서는, maksed token을 활용하여, Masked tokens의 충실도를 동적으로 제어하여, 중요한 영역을 마스킹할 확률을 줄이기 위한 self attention strategy를 제안합니다. 우리의 방법론은 추가적인 시간 소비를 증가시키지 않습니다.


우리는 Patch를 순서에 따라, Attention의 임계값을 기준으로 Masked 후보들을 선택할 수 있습니다. Student Model은 different patch의 중요성을 받고, Masking에 따른 확률을 생성합니다.
Attention Masking 전략은 Pre-training model에 2가지 방식으로 이익이 될 수 있습니다.
1. 모델은 각각의 다른 Patch들 간의 정보를 활용하여 서로 다른 패치의 관계를 이해합니다.
2. 우리의 전략은 필수가 영역을 학습이 가능한 Embedding으로 대체함으로써,
중요한 영역을 마스킹하는 것을 피할 수 있어 모델이 중요한 영역에 초점을 맞출 수 있습니다.
Masked self-supervised transformer
기존 MLM과 다르게, 우리의 방법론은 Original input image를 복원하는데 목적을 둡니다. pixel-level restoration task는 network가 overfitting patch prediction을 과적합하지 않도록 할 수 있습니다. 그렇기에, 우리의 방법론은 Pixel level information을 획득하는데 목적을 둘 수 있으며, finer grain으로부터 공간적 정보를 회복할 수 있습니다. CNN의 inductive bias로 인하여, CNN을 decoder module로써 활용합니다.


Experiments
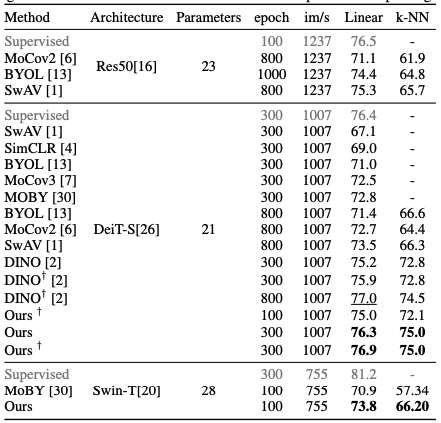

Conclusion
본 논문에서는 visual self-supervised learning의 문제를 해결하기 위한, 지역 정보 추출 방법과 공간적 정보의 손실을 연구합니다.
제안한 방법은 global semantic infomation을 보존하면서 patch 사이에서 local relationship을 파악하기 위해서, attention-guided mask를 추출합니다.

Reference
https://arxiv.org/abs/2106.05656
MST: Masked Self-Supervised Transformer for Visual Representation
Transformer has been widely used for self-supervised pre-training in Natural Language Processing (NLP) and achieved great success. However, it has not been fully explored in visual self-supervised learning. Meanwhile, previous methods only consider the hig
arxiv.org



