
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Meta Learning
- ML
- clean code
- 머신러닝
- classification
- Front
- algorithm
- FineGrained
- SSL
- Python
- Vision
- Depth estimation
- 자료구조
- nerf
- 3d
- CV
- web
- pytorch
- REACT
- GAN
- dl
- 알고리즘
- math
- cs
- nlp
- computervision
- 딥러닝
- FGVC
- PRML
- Torch
- Today
- Total
KalelPark's LAB
[ 논문 리뷰 ] VAE : Auto-Encoding Variational Bayes 본문
[ 논문 리뷰 ] VAE : Auto-Encoding Variational Bayes
kalelpark 2023. 1. 30. 20:33
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/Awesome-ComputerVision
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com
Abstract
* 아직 수학적 지식이 부족하여, 논문을 읽는데 여러 사이트를 참고하였다. (수학공부를 꾸준히 해야겠다.. )
어떻게 하면 확률적 모델에서 효율적인 추론과 학습이 가능한 것이가? 본 논문에서는 미분하기에 어려운 것들을 다루는 통계적 추론과 학습 알고리즘을 제시합니다. 본 논문에서는 2가지를 기여합니다.
1. variational lower bound의 reparmeterization이 일반적인 gradient 방법론들을 사용하여 직접적으로
최적화 될 수 있는 lower bound estimator를 만든다는 것입니다.
2. 각datapoint가 연속형 잠재 변수를 가지는 i.i.d 데이터셋에 대하여, 제한된 lower bound estimator를 사용하여,
게산이 불가능한 posterior에 fitting시킴으로써 posterior inference가 특히 효율적으로 만들어질 수 있다는 점을 보여줍니다.
Introduction
어떻게 연속적인 잠재변수 또는 다루기 어려운 분포에서 효율적인 추론 및 학습이 확률 모델에서 가능한 것인가? 변형 베이지안(VB) 접근법은 다루기 어려운 후방에 대한 근사치를 최적화하는 방안을 제시합니다. 불행하게도, 일반적인 mean-field 접근법은 근사적인 기대값의 해를 요구하며 계산이 불가능합니다.
본 논문에서 소개하는 SGVB(Stochastic Gradient Variational Bayes) estimator는 연속형 잠재 변수나 파라미터를 가지는 어떤 모델에서도 효율적인 approximate posterior inference를 위해 사용될 수 있습니다.
본 논문에서는 AEVB(Auto Encoding Varational Encoder)를 사용하는 알고리즘을 제안합니다.
AEVB 알고리즘은 단순한 ancestral sampling을 활용하여 매우 효율적인 approximate posterior inference를 수행하게 하며, recognitional model을 최적화하기 위해 SGVB estimator를 사용함으로써 추론과 학습을 특히 효율적으로 할 수 있습니다.
Method
본 section의 전략은 연속적인 잠재 변수를 가진 모델을 위한 하한 추정기를 도출하는데 활용할 수 있습니다. 하단의 그램은 grahpical model의 유형을 보여줍니다. ϕ의 경우 generative model parameter와 함께 학습된다.
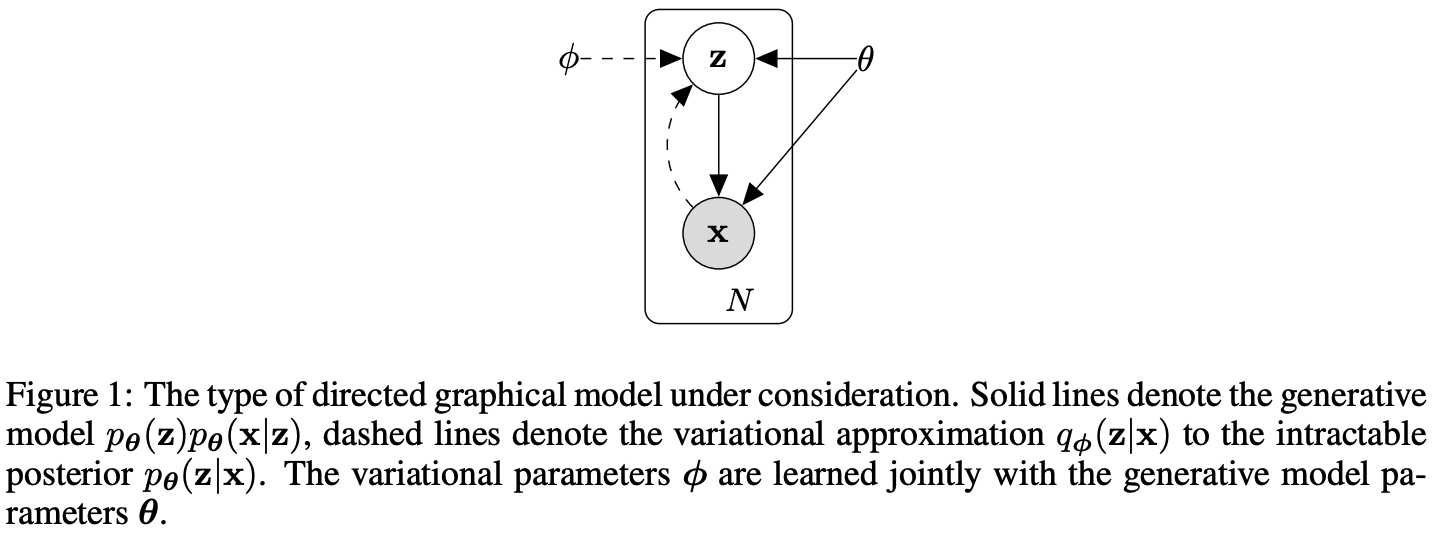
Problem scenario
연속형 변수 혹은 이산형 변수 x의 N개의 i.i.d sample로 구성된 데이터셋을 고려해보자.
관측되지 않은 연속형 랜덤 변수를 포함하는 데이터가 생성되었다고 가정을 해보자.
Process는 2개의 step으로 구성됩니다.
1. 어떤 사전 분포로부터 z값을 생성합니다.
2. x는 어떤 조건부 분포로부터 생성됩니다.
우리는 prior과 likelihood가 parametric families of distribution으로부터 왔다고 가정하며, 그들의 PDF는 0와 z에 대해서 거의 모든 곳에서 미분 가능하다고 가정합니다. 불행하게도, true parameters와 잠재 변수들의 값은 우리에게 알려져 있지 않습니다.
매우 중요하게도, 우리는 주변 확률이나 사후 확률에 대해서 일반적인 단순화한 가정을 만들지 않습니다.

이러한 문제를 해결하기 위해 해결책을 제안합니다.
1. Parameter에 대한 Efficient approximate 추정이다. 예를 들어, natural process를 분석하는 경우와 같이 매개 변수 자체에 관심이
있을 수 있습니다.
2. Parameter의 선택을 위해 사용되는 관측 값 x가 주어진 경우,
잠재 변수 z에 대한 효율적인 approximate posterior inference가 가능합니다. 이는 coding이나 data representation task에서
유용합니다.
3. 변수 x의 효율적인 approximate marginal inference를 위해 우리는 x에 대한 prior가 요구되는 모든 종류의 inference task를 수행
할 수 있도록 합니다.
The Variational Bound

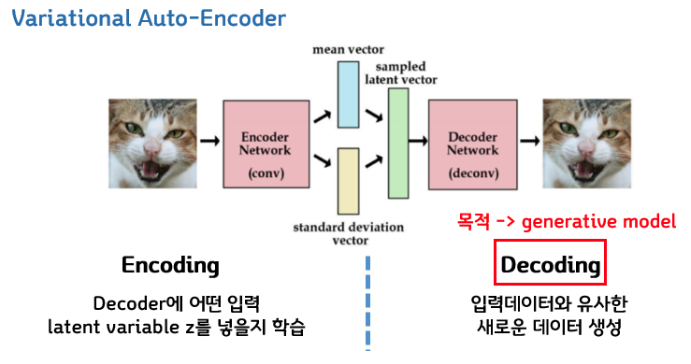
간단하게 정리하자면, VAE(Variational Auto Encoder)는 평균과 표준편차라는 2개의 Output Vector를 추출하여 2가지 Vector를 결합하여 normal distribution을 생성한 후, 새로운 Vector Z를 생성한다. 새로운 Vector Z가 다시 Decoder를 통과하여 데이터를 생성한다.
Experiments
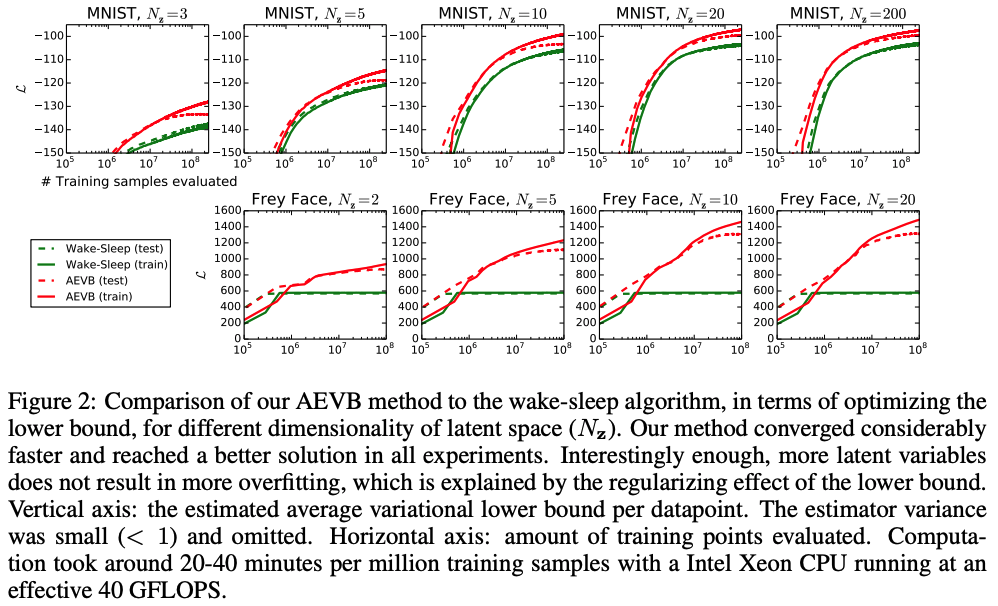
Conclusion
연속형 잠재 변수를 효율적으로 inference하기 위해, 새로운 기법을 사용합니다. 제안된 estimator는 standard stochastic gradient method를 사용해 최적화하는 것이 가능합니다. 우리느 효율적인 추론과 학습이 가능한 알고리즘을 소개하며, SGVB estimator를 사용하여 모델을 학습합니다.
SGVB(Stochastic Gradient Variational Bayes)와 AEVB(Auto Encoding Variational Bayes)를 활용하면, 어떤 연속형 잠재변수를 가지는지에 대해서 추론하는 것이 가능하기에, 복잡한 노이즈 분포를 학습하는데 상당히 효율적으로 보인다고 한다.
참고
https://arxiv.org/abs/1312.6114
Auto-Encoding Variational Bayes
How can we perform efficient inference and learning in directed probabilistic models, in the presence of continuous latent variables with intractable posterior distributions, and large datasets? We introduce a stochastic variational inference and learning
arxiv.org
https://cumulu-s.tistory.com/24
2. Auto-Encoding Variational Bayes (VAE) - paper review
두 번째로 다뤄볼 논문은 VAE라는 이름으로 잘 알려진 Auto-Encoding Variational Bayes라는 논문입니다. 너무 유명한 논문이라 다양한 자료들이 많이 있지만, 가급적이면 다른 분들이 가공해서 만든 자료
cumulu-s.tistory.com
https://di-bigdata-study.tistory.com/4
[VAE] Auto-Encoding Variational Bayes 논문 정리(1)
오늘은 VAE 논문을 정리해보려고 한다. 지난번에 정리했던 ResNet 논문에 비해서 수식이 굉장히 많이 나오고, 통계지식들이 많이 요해지는 논문이라서 개인적으로 이해하는데 굉장히 오래걸렸다..
di-bigdata-study.tistory.com
'Data Science > Generative Adversarial Networks' 카테고리의 다른 글
| [ 논문 리뷰 ] Taming Transformers for High-Resolution Image Synthesis (0) | 2023.04.09 |
|---|---|
| [ 논문 리뷰 ] Wasserstein Auto-Encoders (0) | 2023.03.13 |
| [ 논문 리뷰] Conditional Image Synthesis With Auxiliary Classifier GANs (0) | 2023.01.29 |
| [ 논문 리뷰 ] Conditional Generative Adversarial Nets (0) | 2023.01.28 |



