
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- math
- Vision
- 알고리즘
- FineGrained
- nlp
- Torch
- 자료구조
- classification
- Meta Learning
- Python
- CV
- GAN
- Front
- web
- 머신러닝
- FGVC
- ML
- PRML
- 3d
- clean code
- algorithm
- nerf
- cs
- dl
- SSL
- REACT
- computervision
- pytorch
- 딥러닝
- Depth estimation
- Today
- Total
KalelPark's LAB
[논문 리뷰] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 본문
[논문 리뷰] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
kalelpark 2023. 1. 21. 20:28
GitHub를 참고하시면, CODE 및 컴퓨터 비전 관련 논문들이 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/Awesome-ComputerVision
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com
Abstract
본 논문에서는, 여러 Input 이미지의 sparse set을 데이터로 활용하여 연속적인 움직이는 장면을 최적화하는 함수를 사용하여, 복잡한 장면을 종합하여 최적의 형태를 영상 또는 이미지를 보여줍니다. 본 논문의 알고리즘에서는 Input을 5D coordinate을 FCN의 Input으로 사용합니다.
본 논문에서는 Camera rays의 5D coordinates를 활용하고, Image 내에 밀도와 color를 Output에 투영하기 위해, 일반적인 classic volume rendering techiques를 사용하여, 종합적인 이미지를 보여줍니다. Volume Rendering이 각각의 사진마다 다르기 때문에, 이미지의 표현을 최적화할 때는 단지, Camera의 ray로부터 알려진 이미지의 좌표값들만을 활용할 수 있습니다.
본 논문에서는 복잡한 기하학적 정보와 외관의 정보를 바탕으로 하여 Rendering을 어떻게 효율적으로 해야 최적화할 수 있는지를 보여줍니다.
Introduction
Image의 Rendering의 오류를 최소화하기 위한 5d scene representation을 최적화하기 새로운 방식을 활용하여, long-standing problem을 다룹니다. 우리는 Continuous 5D function을 활용하여 정적인 이미지를 표현합니다. 모든 Convolutional layer없이 Deep fully-connected Neural Network를 최적화합니다.
핵심 원리
수 많은 카메라의 광선으로부터 3D potins의 sampeld set을 생성합니다. 그리고 3D points를 2D를 보는 관점으로 neuralNetwork에 Input으로 사용하여 Color, Density의 Output을 생성합니다. 그리고 2D image내에 Color와 Density를 축적함으로써, classical volumne rendering techniques를 적용합니다.

본 연구에서는 여러 장면에 대한 Neural Radiance Fields Representation을 최적화하기 위한 구현은 높은 해상도로 충분히 최적화하기 상당히 힘들뿐만 아니라, Camera ray가 상당히 부족하다. 우리는 higher frequency function을 표현하기 위해서 MLP를 화용하여 5D coordinates으로 input을 변환합니다.
즉 요약하자면,
1) 2D Image와 카메라로 얻은 시점에 대한 정보로 3D Voxel 좌표의 값을 계산할 수 있고, 반대로 3D 좌표들의 Color와 Density 값으로
각 2D Pixel의 RGBA를 표현할 수 있습니다.
2) 모델이 학습을 진행할 때, 입력으로는 카메라 시점과 Voxel 좌표를 입력으로 취하고, RGB와 Volume Density를 출력하는
함수 F를 정의하여, FCN(Fully Connected Network)로 함수 F모델을 학습합니다.
3) Inference시, 새로운 카메라 시점이 입력으로 주어지면, 학습한 모델로 3D voxel 좌표에서의 RGB 값을 계산한 후,
대응되는 2D Pixel 좌표로 Summation함으로써 색상 값을 Prediction을 진행합니다.
본 논문에서는, first continuous neural scence representation이 현실세계의 객체와 유사한 고화질 이미지로 Rendering이 가능하다는 것을 보여줍니다.
Related Work
이전의 방법론들은 현실적인 이미지를 생성하는 것이 불가능합니다. 이전의 방법론과 본 논문의 방법론을 비교합니다.
Neural 3D shape representation
최근의 연구는 연속적인 3D shape의 Representation과 연관되어 있습니다. 하지만, 이러한 모델들은 ground truth가 3D geometry이기에 상당히 접근하는데 제한이 있습니다. 본 연구에서는 5D radiance fields로 encoding하기 위한 최적의 Network 전략으로 higher-resolution geometry와 복잡한 장면에 대해서 새로운 장면으로 render하는 방법을 제시합니다.
View Synthesis and image-based rendering
연속적인 이미지를 고려하면, 이미지들은 단순한 light field sample interpolation techniques에 의하여, 다시 재조정될 수 있습니다. Image reprojection에 기반한 gradient 기반의 mesh optimization은 local minima와 poor conditioning으로 인하여 상당히 활용하기 힘듭니다. 게다가 이러한 전략들은 optimization하기 전 initialization과 고정된 위치를 가진 mesh가 필요합니다. 이러한 이유로, 현실세계에서 보여주기에는 상당히 힘듭니다.
Volumetric approaches는 현실세계의 복잡한 형태와 material을 보여주는 것이 가능하며, gradient based optimization에 적합합니다. 초기의 Volumetric approaches은 observed images를 color voxel grids로 표현합니다. Volumetric techniques가 State of the art를 달성했을지라도, Image를 Scale 하여 고해상도를 보여주는데는 상당한 제한이 있습니다.
본 논문에서는 이러한 parameters내에 continuous volume으로 Encoding함으로써 고해상도로 표현하는데 상당히 제한적이였던 문제를 피합니다.
Neural Radiance Field Scene Representation
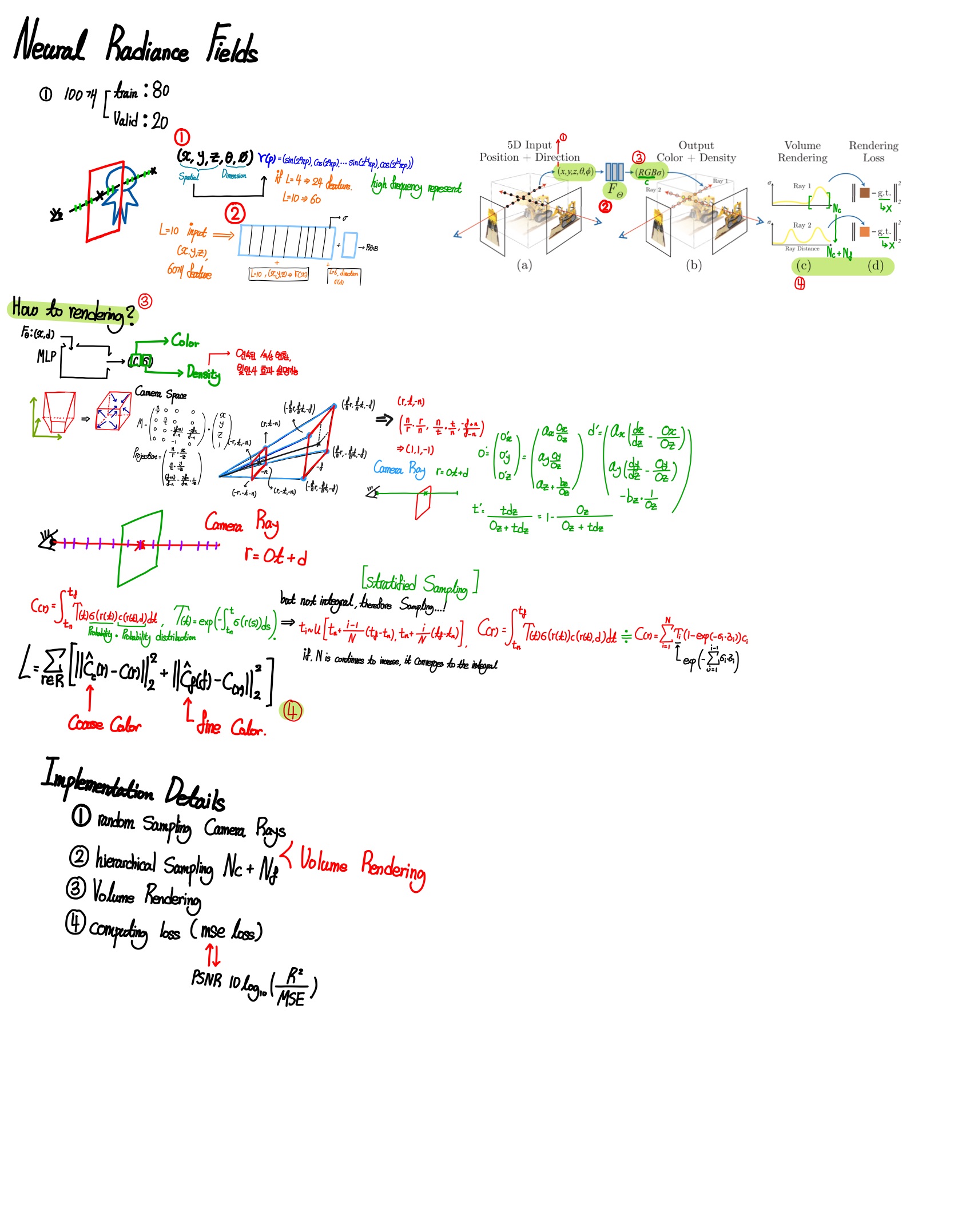
우리는 3D location(X, Y, Z)과 2D direction(θ, φ)를 input으로 사용하는 5D vector-valued function으로 활용하여 연속적인 장면을 표현합니다. 본 논문에서는 3차원 좌표를 Vector d로써 표현합니다. 이후, MLP를 활용하여, input을 volume density와 Color로 mapping하는 것에 최적화를 합니다. Vector를, 8-fully-connected layer에 입력하여, output으로, σ와 색상을 표현하는 256 feature vector를 출력합니다.
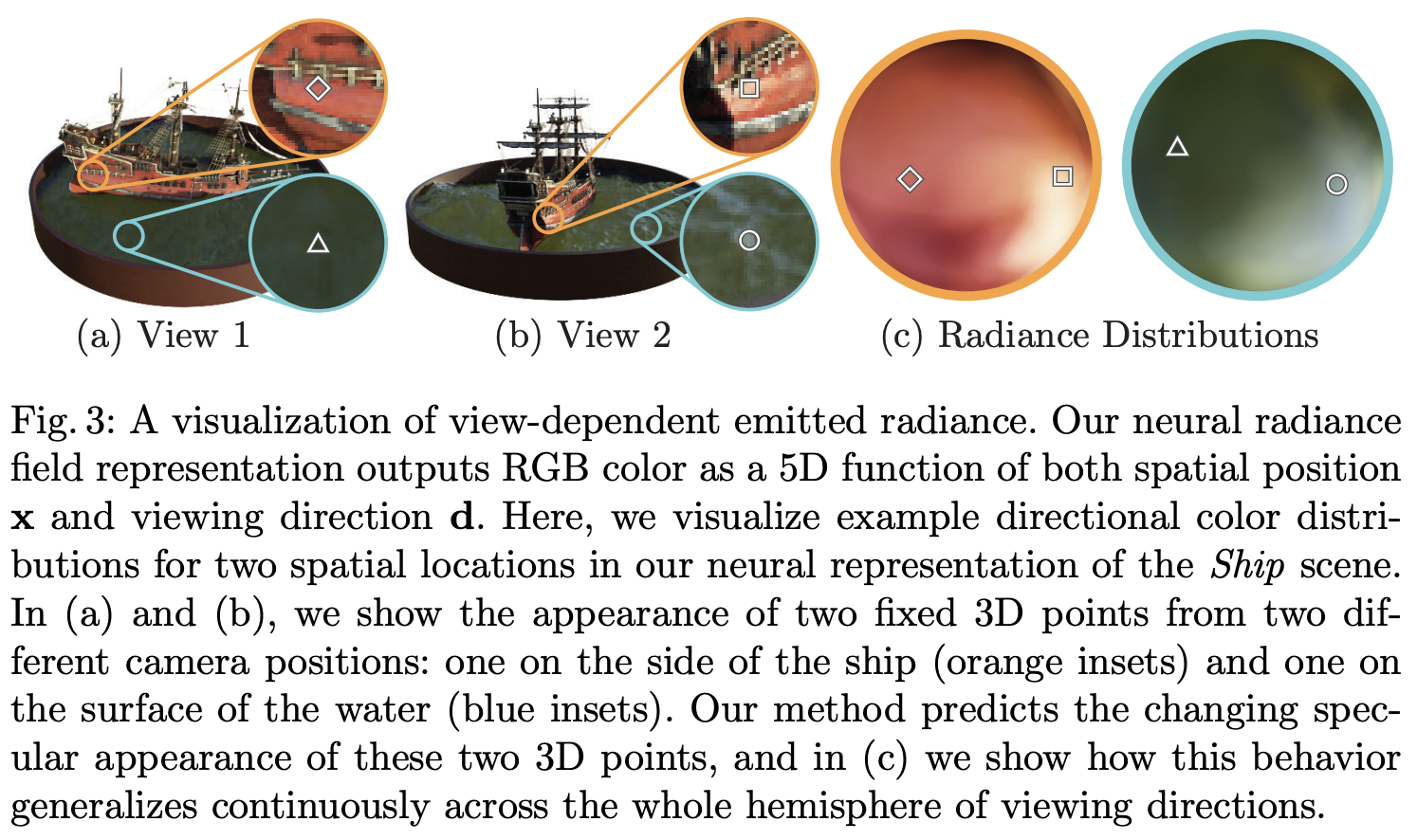

Volume Rendering with Radiance Fields
5D neural radiance field는 공간내의 여러 point와 volume density를 표현합니다. 우리는 classical volume rendering으로 얻은 장면을 통하여 색상을 생성합니다. 부피 밀도 θ(x)는 위치 x에서 극소 입자로 끝나는 광선의 미분 확률로 해석될 수 있다.

연속적으로 Rendering하기 위해서는, 카메라를 통하여 얻은 각각의 픽셀로부터 얻은 정보로부터 integral C(r)를 추정하는 것이 필요합니다. voxel grid를 rendering 하는데 사용하는 quadrature를 사용하여 continous integral로 추정하는 것이 가능합하지만, MLP의 고정된 discrete set으로 인하여, 해상도를 표현하는데 상당히 제한적입니다. 그리하여 우리는 적절한 분포를 sampling하는 방법을 활용하고, 각각의 분포가 uniformly하게 합니다.
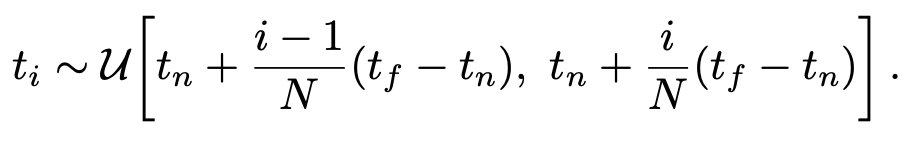
비록, integral을 추정하기 위해 discrete sample을 사용할지라도, MLP가 연속적인 좌표를 표현하기 때문에, stratified sampling은 연속적인 장면을 representation하는 것에 가능합니다.
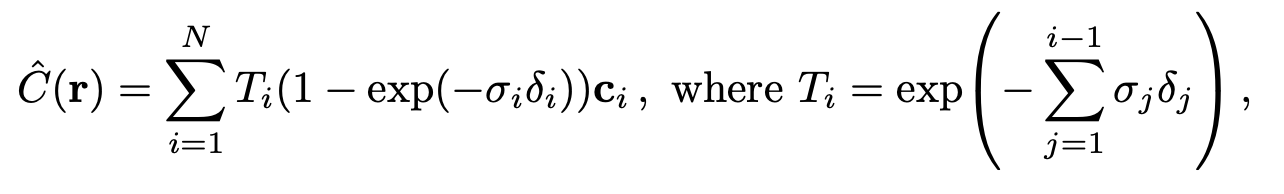
Optimizing a Neural Radiance Field
우리는 복잡한 해상도를 개선하기 위해 2가지 개선사항을 추가합니다.
1) MLP내에 high-frequency function을 표현하기 위해 input coordinates의 positional encoding하는 것입니다.
2) high-frequency representation을 효율적으로 sampling하기 위해, hierarchical sampling procedure를 진행하는 것입니다.
Position Encoding
Neural Network가 보편적인 함수라는 사실에도 불구하고, 우리는 xyz를 입력좌표로 Network에 직접적으로 활용한다면, 색상과 기하학내에서 고주파를 표현하는데 상당한 악영향을 끼친다는 것을 발견하였습니다. 이것은 deep network는 low frequency function쪽으로 학습하여 편향된다는 이전의 연구결과와 일맥상통합니다. 본 논문에서는, Network에 Input으로 사용하기 이전에 high frequency function을 활용하여 higher dimensional space에 Input으로 mapping하는 것이 high frequency varation을 포함하는 데이터 적절하게 fitting될 수 있음을 보여줍니다.
F를 F'*r로 변형하고, r는 higher dimensional space로 mapping해주는 parameter로 변형하여 표현합니다.

r은 x에 속해있는 x, y, z좌표에 대해서 따로 분해되서 사용됩니다.
Hierarchical volume sampling
Single Network로부터 scene을 표현하는 것 대신에, 우리는 "coarse", "fine"한 Network를 2가지 동시에 최적화를 진행합니다. stratified sampling을 활용하여, N location의 set을 sampling하고, "coarse" Network를 평가합니다. "coarse" Network를 고려하여, 우리는 volume과 관련된 부분으로 편향된 samples들을 ray를 통하여 Sampling points를 생산합니다.
이를 위하여, "Coarse" Network는 rays에 따라 Sampling된 모든 색상의 가중치 합으로 rewrite한다.

위의 식을 통하여 얻은 가중치를 Normalizing을 함으로써, ray를 따라 PDF를 생산합니다. inverse transform sampling을 활용하여 distribution으로부터 정보를 sampling을 진행합니다. 우리는 전체의 sample을 사용하여 최종 ray를 계산하여 유효한 값들을 더 많은 Sample에 할당합니다.
Implementation details
각각의 장면으로부터, Continuous volume representation Network를 최적화합니다. 본 모델은 RGB 장면으로부터 얻은 정보들에 대한 Dataset만을 필요로 합니다. Dataset으로부터 모든 pixel의 set으로부터 얻은 camera rays의 batch를 무작위로 sampling합니다. 우리는 volume rendering procedure를 사용합니다.
coarse fine rendering에 대한 rendering된 pixel과 true pixel사이에서의 total squared error를 loss를 활용합니다.
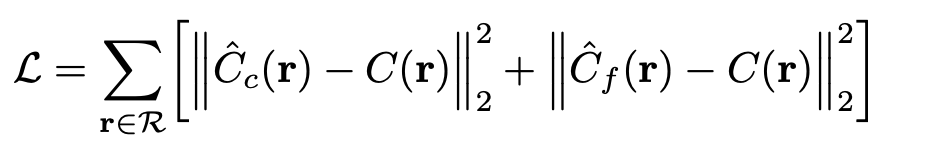
기타 세부사항

Experiments

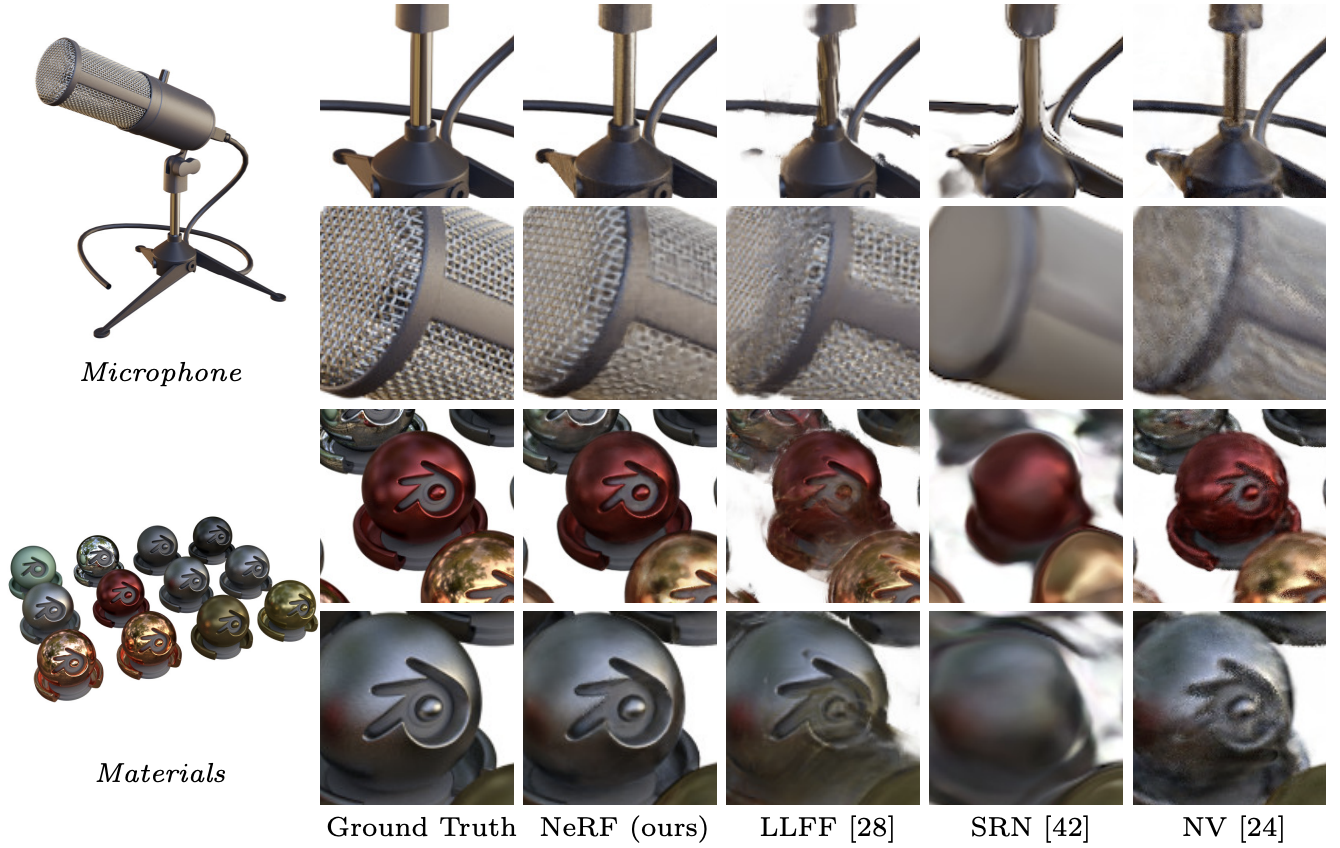
Conclusion
본 연구에서는 객체와 장면을 표현하기 위한 MLP를 사용하는 이전의 작업에 대한 문제점을 다룹니다. 본 연구에서는 5D neural Raidance fiedls로써 표현된 장면들을 다룹니다. 비록 제안된 hierarchical sampling strategy이 rendering을 하는데는 조금 더 효율적일지라도, 여전히 optimize and neural radiance fields를 효율적으로 최적화하는데 더 많은 연구가 필요할 것으로 보인다.
본 연구가 real world image를 기반으로 graphcis pipelines 분야로의 연구를 진행하는데 발판을 만든 것이라고 믿는다.
참고 자료
https://arxiv.org/abs/2003.08934
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
We present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views. Our algorithm represents a scene using a fully-con
arxiv.org
[논문 정리] NeRF 개선 방향 및 기술 동향
NeRF(Neural Radiance Fields) 최초 논문에서는 확장 가능한 여러 가능성을 남긴체로 간단하게 핵심 개념을 소개하였었습니다. NeRF 최초 논문(ECCV2020)에 대한 설명은 이전 포스트 참조 바랍니다. 본 글에
xoft.tistory.com
'Data Science > Neural Radiance Fields' 카테고리의 다른 글
| [ 논문 리뷰 ] PixelNeRF: Neural Radiance Fields from One or Few Images (0) | 2023.01.25 |
|---|---|
| [논문 리뷰] D-NeRF: Neural Radiance Fields for Dynamic Scenes (0) | 2023.01.23 |

