
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- nlp
- Meta Learning
- CV
- Python
- FGVC
- 알고리즘
- Front
- computervision
- Depth estimation
- Vision
- 머신러닝
- nerf
- cs
- GAN
- ML
- classification
- 딥러닝
- clean code
- FineGrained
- 3d
- algorithm
- web
- Torch
- REACT
- pytorch
- 자료구조
- math
- PRML
- SSL
- dl
- Today
- Total
KalelPark's LAB
[논문 리뷰] Optimization as a model for few-shot learning? 본문
[논문 리뷰] Optimization as a model for few-shot learning?
kalelpark 2022. 12. 27. 09:17
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/Awesome-ComputerVision
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com
Abstract
- 일반적으로 큰 Network에서는, Gradient based optimization은 상당히 많은 iteration을 해야 성능이 잘 나옵니다.
본 논문에서는 few shot 접근으로 learner neural Network를 학습하는데 사용되는 optimization algorithm를 학습하는 LSTM 기반의 Meta-learner Model을 제안합니다.
- parameterization을 통하여, 정해진 양의 Update가 이루어지는 적절한 parameter update를 학습하는 동시에
학습을 신속하게 하는 convergence할 수 있는 learner의 general initialization을 학습하는 것이 가능합니다.
- Meta learning Model은 few shot learning이 metric-learning techniques에서 경쟁력이 있음을 증명하였습니다.
Introduction
- gradient-based optimization이 실패하는데는 2가지 주된 이유가 존재합니다.
첫 번째로, 기존의 optimization은 제약된 양의 데이터에서 잘 수행되도록 설계되지 않았습니다.
구체적으로, non-convex optimization problem이 적용될 때, 합리적인 parameter를 사용 시,
좋은 solution으로 수렴되는 속도를 보장하지 못합니다.
두 번째로, 각각의 Dataset을 고려할 때, dataset에 대해서 Network의 Parameter는 random initialization되는데, 이것은
약간의 update 이후, good solution으로 수렴하는 능력을 손상시킵니다.
transfer learning은 fine tuning을 함으로써, 문제를 해결할 수 있지만, pretrained Model이 target task와 크게 다를 경우,
benefit이 크게 감소합니다.
- 어떤 Dataset이든지, 학습을 시작하기에 좋은 point가 될 수 있는 beneficial common initialization을
학습하는 것이 필요합니다. 이러한 방법은, transfer learning과 같은 benefit이 되며,
fine-tuning을 위한 최적의 시작점으로 initialization하는 것을 보장합니다.
- Meta learning은 two-level로 학습하는 것을 제안합니다.
첫 번째로는, 각각의 분리된 task로부터 knowledge를 빠르게 획득하는 것입니다.
이러한 Process는 학습된 정보를 느리게 추출하는 process에 의해 guide됩니다.
본 논문에서는 learner neural network classifier를 최적화하는 것을
학습하는 LSTM기반의 meta-learner optimizer를 제안합니다.
Meta-learner는 모든 Task내에서 logn-term knowledge와 task냉세ㅓ short-term knowledge를 포착합니다.
- 설정된 update 횟수만큼으로 generalization performance을 얻을 수 있는 최적화 알고리즘의 기능을 direct captuer하는 Objective를 사용함으로써,
Meta-learner Model은 learner classifier를 각각의 task에 빠르게 good solution으로 수렴하게 학습합니다.
이러한 meta learner model의 형식은 learner classifier를 위한 task-common initialization을 학습하는 것이 가능하며, 모든 task내에서 공유되는 fundamental knowledge를 capture합니다.
Task Description
- Meta Learning에서는 여러 개의 regular dataset을 포함하는 meta-sets으로 D_{train}, D_{test}로 나눕니다.
K-shot, N-Class classification task에서의 의미로는, N개의 class에서, K개의 labeled samples를 의미합니다.
그러므로, D_{train}은 K*N의 Examples를 가지고 있습니다.
그리고, D_{test}는 evaluation을 위한 examples의 개수를 가지고 있습니다. D_{train}, D_{test}을 설명하기 위해서,
episode라는 용어를 활용합니다.
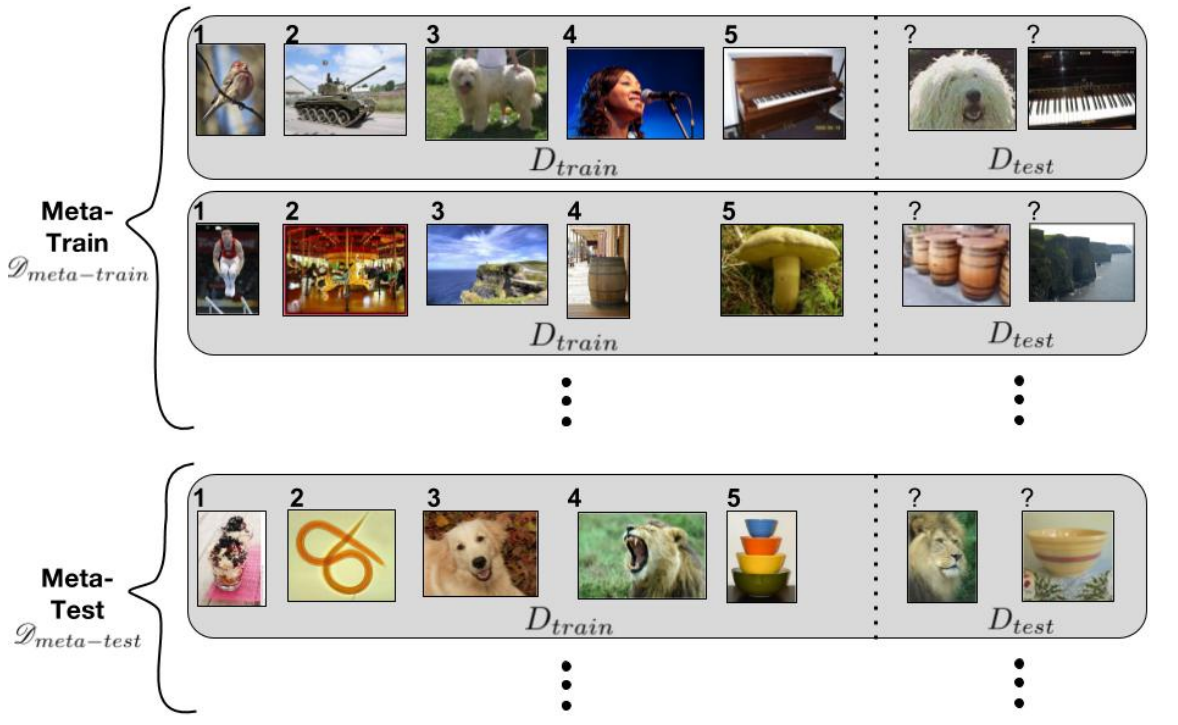
- Meta Learning에는 Meta-training, Meta-validation, Meta-testing이라는 meta-sets이 존재합니다.
D_{meta-train}에서 training set 중 1개를 input으로 활용하여, D_{test}를 높은 성능을 달성하는데 목표를 두고
meta-learner를 학습시키는 과정에 중점을 둡니다.
이후, D_{meta-validation}을 활용하여, meta-learner의 hyper parameter를 생성하고,
D_{meta-test}의 일반적인 성능을 평가합니다.
Model

- theta를 최적화하기위해, 이전의 theta에서 alpha(learning rate)* 이전의 theta의
각각의 paramameter에 대한 loss를 뺍니다.
- 이러한 방식은 LSTM과 매우 유사합니다.
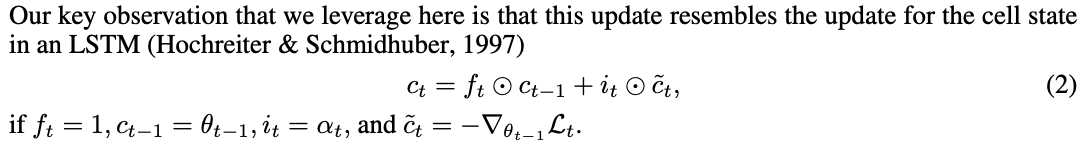
그러므로, Neural Net-work를 학습하는 update rule을 학습하는 meta-learner LSTM을 training할 것을 제안합니다.

i_{t}는 learning rate가 여러 parameter로 이루어진 함수를 의미합니다. 이러한 정보들을 통하여, meta-learner는 learnin rate를 finely control하는 것이 가능합니다. 그리하여, divergence를 회피하면서 learner를 빠르게 학습하는 것이 가능합니다.
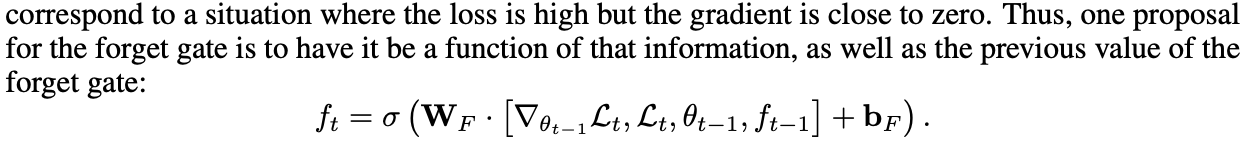
직관적으로, learner의 paramter를 축소하고, 이전 값의 일부를 잊는 것을 정당화하는 것은 learner가 bad local optima에서 큰 변화가 필요한 경우이다. 이러한 경우는 loss는 매우 높은 상태인데, gradient는 0에 가까운 경우이다. 그러므로, forget gate에 대한 제안은 forget gate에 대한 정보 뿐만아니라, 이전의 information에 대한 function이다.
또한 LSTM의 C_{0}의 initial value는 meta learner의 parameter로 볼 수 있습니다. 이것은 classification의 initial wiehgt으로 볼 수 있습니다.
meta-learner가 초기 값을 학습하면, learner의 최적의 초기 가중치를 결정하여, 최적화를 빠르게 진행할 수 있는 beneficial starting point로부터 시작하는 것이 가능합니다.
마지막으로, meta-learner's update rule이 LSTM의 cell state update와 동일하지만, GRU의 hidden state update와 유사하다.
하지만, forget과 input gate가 하나로 되어 있지 않는다는 점에서 예외이다.
Parameter Sharing & Preprocessing
- learner gradient의 coordinates를 거쳐 parameter를 공유합니다. 이를 활용하여, compact LSTM model을 활용하며,
각각의 coordinate를 활용하여, 적절한 목적을 달성할 수 있습니다.
- Gradient와 loss가 매우 다른 magnitude를 갖게 될 수 있으므로, 값을 normalizing하여,
meta-learner가 학습을 제대로 할 수 있게 보조해야 합니다.

Training
- few shot learning task에 LSTM meta-learner model이 효과적으로 학습하기 위해서는,
test time과 training time을 matching하는 것이 중요합니다.
- Meta learning을 평가하는 동안에, good meta learner mode에는
D_{train}에 대한 gradient와 loss가 주어졌을 때, D_{test}에서 좋은 성능을 classification으로 update를 진행합니다.

- 그러므로, test time 환경에 맞추기 위해서는, 우리가 사용하는 training loss는 D_{test}에서 생성되는 classification의
L_{test}입니다. D_{train}을 진행하는 동안, learner로부터 LSTM meta-learner는 L_{test}를 받게 되고,
새로운 theta가 제안됩니다.

Initialization of meta learning LSTM
- LSTM으로 학습하고자 할 때, small random weights으로 LSTM을 초기화합니다.
그리고, forget gate bias를 큰 값으로 세팅합니다. 그리하여, forget gate는 1에 가깝게 됩니다.
그리하여, gradient flow가 가능하게 됩니다.
추가적으로 forget gate bias를 setting시, input gate bias를 작은 값으로 초기화할 필요가 있음을 발견하였습니다.
종합적으로, meta learner는 small learning rate에 가까운 normal gradient에서 시작됩니다. 이러한 방식은
학습에 상당한 안전성을 기여합니다.
Batch Normalization
- 서로 다른 데이터 세트에서 정보가 누출되는 방식으로 meta testing 동안에는 mean과 standard deviation statistics
을 수집하지 않습니다.
meta Learning setting에서 learner network에 대한 batch normalization을 주의할 필요가 있습니다.
이러한 Issue를 막는 한가지 방법은 meta-testing동안에 statistic을 집계하지 않는 것입니다.
하지만, meta-training시에는 단지 평균만을 사용해야 합니다.
meta training 과 meta testing의 조건이 변경되어 meta-learner가 meta-testing time을 가지지 않는
batch statistic에 의존하는 optimization method를 학습하기 때문에, 성능에 악영향을 끼칩니다.
- meta-training 과 meta-testing의 환경을 비슷하기 유지하기 위해서는, 각각의 dataset에 대해서 collect statistic을
수집하는 것이 better strategy이다.
하지만, 다음 dataset을 고려할 때 실행중인 statistics을 지우는 것이 좋은 전략이라고 한다.
- 그러므로, meta-training 동안에, training과 testing에서 batch statistics을 활용합니다. 반면에 meta-testing에서는
training set에 대한 batch statistics를 사용하고, testing 동안에는 running averages를 활용합니다.
이러한 방식은 각각의 dataset으로부터 정보의 누출을 방지합니다. 뿐만 아니라, meta-learner가 training과 testing사이에서의 환경을 동일하도록 합니다.
우리는 약간의 training step을 진행하기 때문에, running average를 게산하여, higher preference를 얻는 것이 가능합니다.
Few-shot learning
- few shot learning에서 best performing methods는 주로, metric learning methods기반입니다.
Deep siamese networks는 distance metric에 따라서,
동일한 class에 대한 항목은 가까운 반면에, 다른 클래스의 항목은 멀도록 example을 embedding하여,
convolutional network를 train하였습니다.
- Convolutional Network에 의하여 생성된 embedding cosine similarities를 포함하는
가까운 neighbor사이에서 차별화가 가능한 loss를 정의함으로써, training과 testing의 conditions을 match 하였습니다.
Experiments Result
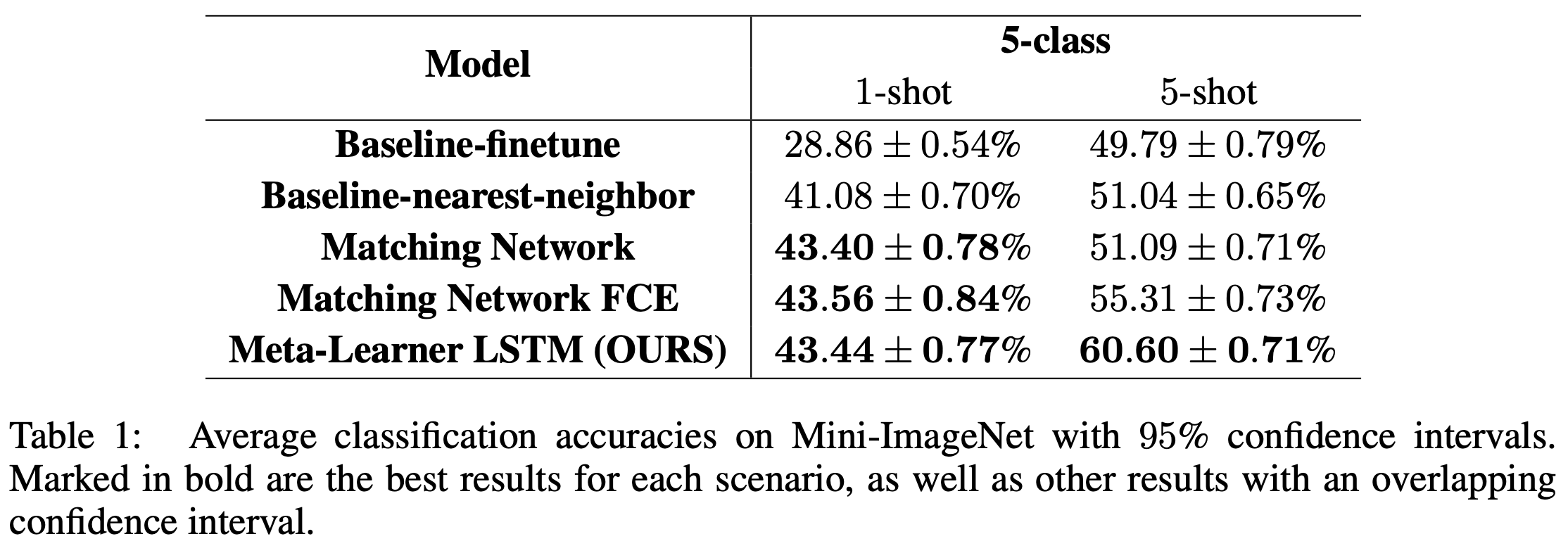
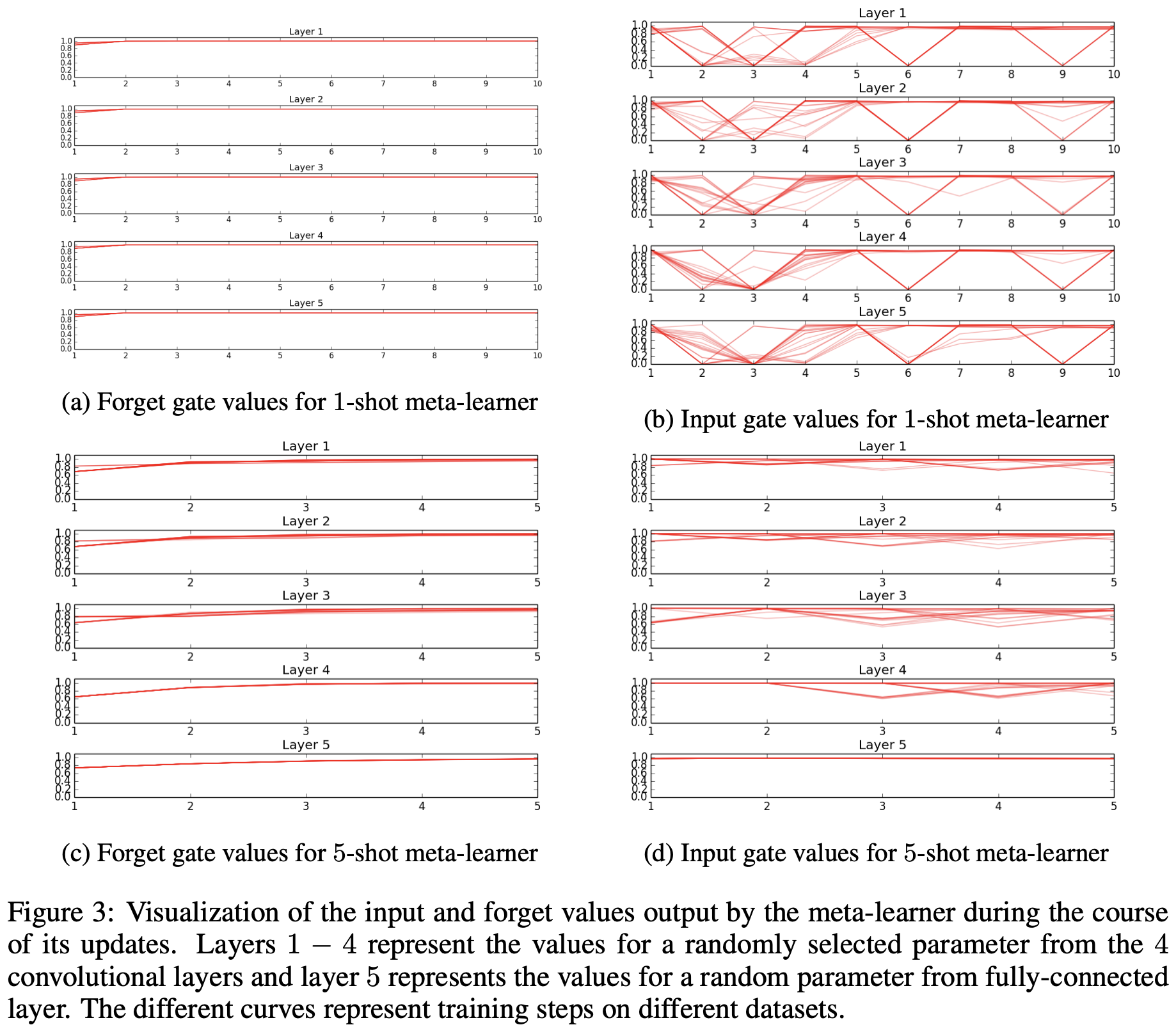
Visualization of Meta-Learner
- meta learner에 의하여 학습하는 optimization strategy를 Visualization 하였습니다.
update step마다, i_{t}, f_{t}의 값이 변화되는 것을 알 수 있고,
training 동안 meta-learner가 learner를 어떻게 update하는지에 대한 이해를 시도할 수 있습니다.
- 1-shot, 5-shot ahen forget gate values에서 meta-learner는
서로 다른 layer에서 일관된 것처럼 보이는 simple weight decay strategy를 활용하였습니다.
input gate의 값으로는 meta-learner's strategy를 수집하고, 해석하는데 상당한 어려움이 존재합니다.
다양한 dataset에서 상당한 variavility가 많은 것으로 보인다. meta-learner는 고정된 optimization strategy를 활용합니다.
추가적으로 two task 사이에서 차이가 보입니다. meta-learner는 각각의 setting에서 다양한 환경을 고려하기 위해,
다양한 method를 채택합니다.
Conclusion
- 우리는 Meta-learning에 기반한 LSTM-based model을 설명하였습니다. LSTM meta-learner는 classifier의 parameter의 learning update를 표현하기 위해 활용됩니다. 학습자의 parameter에 관한 좋은 initinalization을 발견하기 위해 학습됩니다.
뿐만 아니라, 새로운 classification task에 대한 적은 양의 training set을 고려하여, learn's paramters를 Update하기 위한 성
공적인 mechanism입니다.
본 연구에서는 few-shot 과 few-classes setting에 초점을 두었습니다. 하지만, 넓은 spectrum에서 meta-learners를 학습할 수 있다는 점에서 가치가 있습니다.
Reference
https://openreview.net/pdf?id=rJY0-Kcll
'Data Science > Meta Learning' 카테고리의 다른 글
| [ 논문 리뷰 ] One-shot Learning with Memory-Augmented Neural Networks? (0) | 2022.12.29 |
|---|---|
| [Meta Learning] Neural Turing Machines이란? (2) | 2022.12.28 |
| [ Meta Learning ] 모델 기반 메타 러닝 이해하기 (0) | 2022.12.28 |
| [Meta Learning] MetaDataLoader 구현 (0) | 2022.12.28 |
| [Meta Learning] What's Meta Learning? (0) | 2022.12.25 |



