
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 머신러닝
- Torch
- CV
- algorithm
- computervision
- Depth estimation
- Meta Learning
- web
- Vision
- nlp
- 3d
- Python
- dl
- nerf
- FineGrained
- Front
- cs
- clean code
- classification
- FGVC
- ML
- 자료구조
- REACT
- SSL
- GAN
- PRML
- math
- 알고리즘
- pytorch
- 딥러닝
- Today
- Total
KalelPark's LAB
[ Pandas ] Study with Groupby 본문

Pandas Groupby
- Group DataFrame using a mapper or by a Series of columns.
(Mapper를 사용하거나, 일련의 열을 기준으로 데이터 프레임을 그룹화합니다.)
- Groupby는 결과를 결합하고, 함수를 적용하고, 객체를 분할하는 역할을 합니다.

Groupby for Statistics
- 데이터 프레임에 .groupby(Column) + 통계함수로 그룹별 통계량을 확인할 수 있습니다.
- 통계 결과는 통계계산이 가능한 수치형(numerical) 컬럼에 대해서만 산출합니다.
df.groupby("sex").mean()
df.groupby("sex").var()

.agg()를 활용하여 다중 통계량을 구할 수 있습니다.
- .agg()에서 문자열로 지정할 수 있는 함수 목록을 다음과 같습니다.
- .agg()로 다중 통계량을 구할 때 Column별로 다르게 통계 함수를 적용할 수 있습니다.
df.groupby('sex').agg(['mean', 'var'])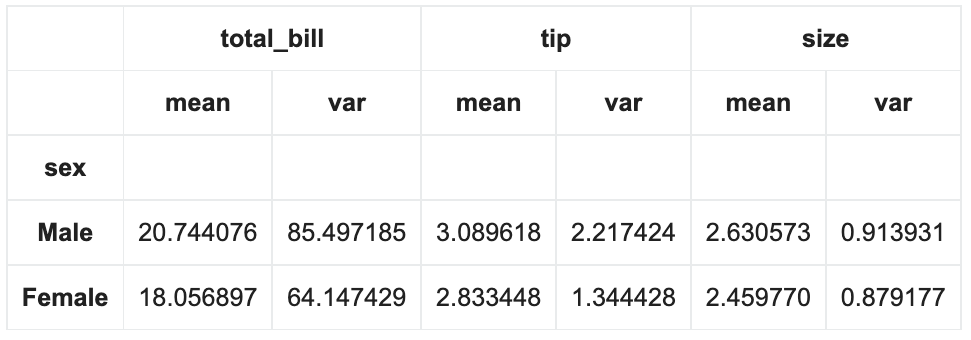
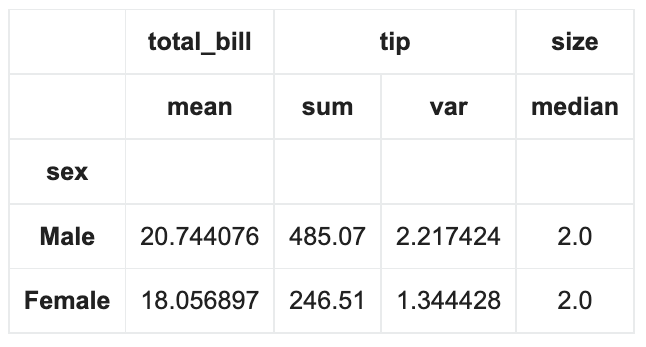
df.groupby('sex').agg({'total_bill': 'mean',
'tip': ['sum', 'var'],
'size': 'median'
})
Apply for Statistic
- Apply Column때, 결측치를 단순 통계량이나 임의의 값으로 채울 수 있지만,
.groupby()를 활용하여 그룹별 통계량으로 채울 수 있습니다.
EX>
먼저, groupby("sex")로 성별 그룹으로 나눈 뒤, 나이 컬럼에 대해서 각 그룹의 나이 평균으로 결측치를 채웁니다.
df.groupby('sex')['age'].apply(lambda x: x.fillna(x.mean()))참고 자료
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.groupby.html
pandas.DataFrame.groupby — pandas 1.5.2 documentation
When calling apply and the by argument produces a like-indexed (i.e. a transform) result, add group keys to index to identify pieces. By default group keys are not included when the result’s index (and column) labels match the inputs, and are included ot
pandas.pydata.org
https://teddylee777.github.io/pandas/pandas-groupby
판다스(Pandas) .groupby()로 할 수 있는 거의 모든 것! (통계량, 전처리)
판다스(Pandas) .groupby()로 할 수 있는 거의 모든 것! (통계량, 전처리)에 대해 알아보겠습니다.
teddylee777.github.io