
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- SSL
- web
- Python
- FineGrained
- math
- Front
- Vision
- computervision
- nlp
- ML
- algorithm
- CV
- PRML
- 3d
- cs
- nerf
- pytorch
- 자료구조
- clean code
- Torch
- FGVC
- 머신러닝
- 알고리즘
- dl
- Meta Learning
- REACT
- GAN
- Depth estimation
- classification
- 딥러닝
- Today
- Total
KalelPark's LAB
[ Algorithm ] Hashing? 본문

Hashing이란?
- 선형 탐색이나, 이진 탐색은 모두 키를 저장된 키 값과 반복적으로 비교함으로써, 탐색하고자 하는 항목에 접근한다.
이러한 방법들은 최대 가능한 시간 복잡도가 O(logN)에 그친다.
- 해싱은 키에 산술적인 연산을 적용하여 항목이 저장되어 있는 테이블의 주소를 계산하여 항목에 접근한다.
용어
Identifier density
- Identifier density is the ratio n/T, where n is the number of identifiers in the table.
T is number of possible identifiers. (Table에 속해있는 identify의 개수)
Loading factor
- a = n / (s * b) 의 저장공간을 가지고 있습니다.
Synonyms
- 만약, i1 과 i2의 해쉬의 값이 동일하다면, synonyms(동의어)라고 할 수 있습니다.
Overflow
- Bucker이 꽉 찬 경우, 한 개를 더 추가하는 경우, 넘치기에, Overflow가 발생한다고 합니다.
Collision
- 두개의 같지 않은, hash가 같은 bucket에 들어가는 경우, Collision이 발생했다고 합니다.
Mid-Square
- 두개의 같지 않은, hash가 같은 bucket에 들어가는 경우, Collision이 발생했다고 합니다.
Hashing Function의 Requirement?
- Compute가 쉬워야 합니다.
- Collision의 개수가 최소화해야 합니다.
- Unbiased 해야 합니다.
Mid-Square
- Key 값을 제곱한 후, 결과 값의 중간 부분에 있는 N개의 비트만을 선택하여, 해시로 활용하는 방법입니다.
Table 크기의 자릿수만큼 중간값을 가져옵니다.


Division
- 나눗셈 방법(Division Method)는 나머지 연산을 이용하여, 해시를 만드는 방법입니다.
검색 키를 해시 테이블의 크기 m으로 나눈 나머지를 해시로 사용합니다.
* 이떄, 주의할 점으로는, 짝수로 값을 설정하는 경우, 짝수의 값만이 계속해서 편향되서 나오므로, 홀수로 설정하는 것이 좋습니다,.
- h(k) = k mod m (k : key, m : table) 입니다.

Folding
- 접기(Folding)은 검색 Key를 분해한 후, 좁합하는 방식으로 해시를 만드는 방법입니다.
- 접기에는 2가지 방식이 존재(Shift Folding, Boundary Folding)합니다.
Shift Folding
1. 해시 테이블 크기의 자릿수로 키를 분해합니다.
2. 분해된 키들을 더한다.
3. 더한 값이 테이블 크기를 초과한다면, 초과한 자릿수는 버립니다.
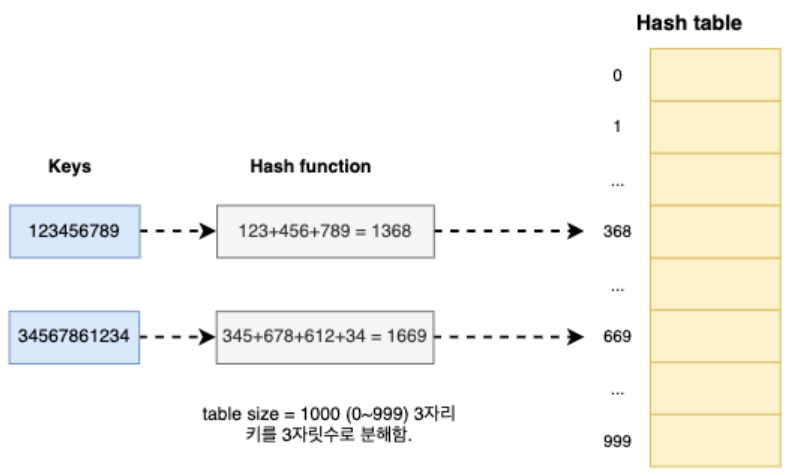
Boundary Folding
1. 해시테이블 크기의 자릿수로 키를 분해합니다.
2. 나누어진 각 부분의 경계 부분 값을 역으로 정렬합니다.
3. 분해된 키들을 더합니다.
4. 더한 값이 테이블 자릿수를 초과한다면 초과한 자릿수는 버립니다.
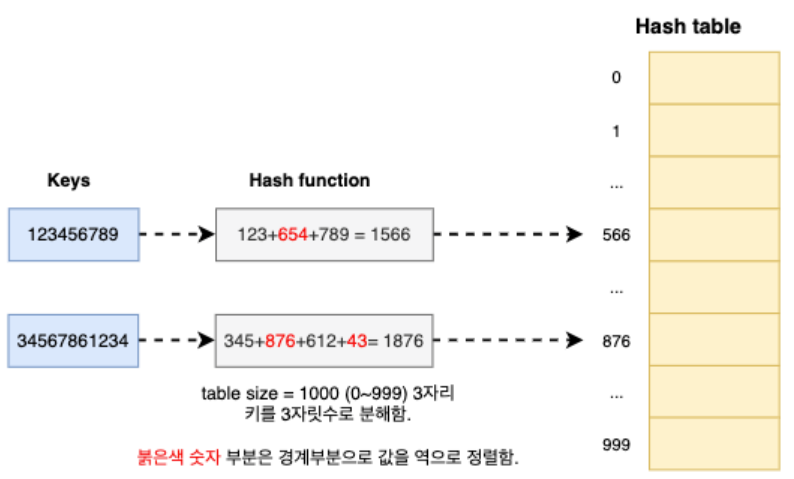
Digit Analysis
- 키 중에서 편중되지 않은 수들을 해시 테이블의 크기에 적합하게 조합하여 활용하는 방법이다.
- 수를 검사하고, 치우친 분포를 가진 숫자를 삭제합니다.
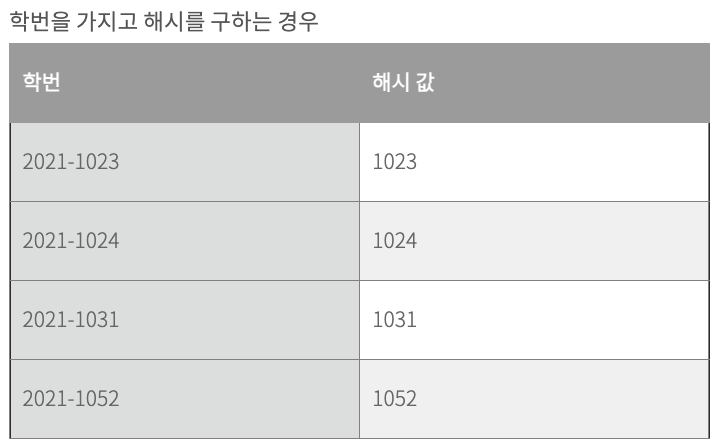
- 앞에 4자리는 연도이고, 뒤 번호는 개인 번호입니다.
- 고르게 분포되어 있는 값을 활용하기 위해, 편중된 값은 제거한 수를 활용하여, 해시 값을 생성합니다.
Overflow Probing
Linear Probing
- 선형적인 형태로 충돌이 발생하면, 1씩 증가하면서 빈 Slot을 찾는 방식입니다.
- h(k) -> 충돌 -> h(k)+1 -> 충돌 -> h(k)+2
Random Probing
- 무작위로, slot을 찾아 값을 대입합니다.
Quadratic Probing
- Linear Pobling에서 복잡하게 발전된 형태로, i의 제곱 값으로 탐색하는 방법입니다.
- i의 제곱 값으로 탐색하는 방법입니다.
하지만, 이 방법은 secondary clustering 단점이 있는데, 처음과 같은 해쉬값이 나온다면,
i값에 따라서 해쉬값이 바뀌기 때문에 충돌이 반복적으로 발생합니다.

Chaining
- 한 공간당 들어갈 수 있는 갯수를 제한하지 않고, LinkedList로 만들어 계속 key값을 추가하는 방법입니다.
Chain은 말 그대로 LinkedList로 Key값을 계속 연결해 나가기 때문에 붙여진 이름입니다.
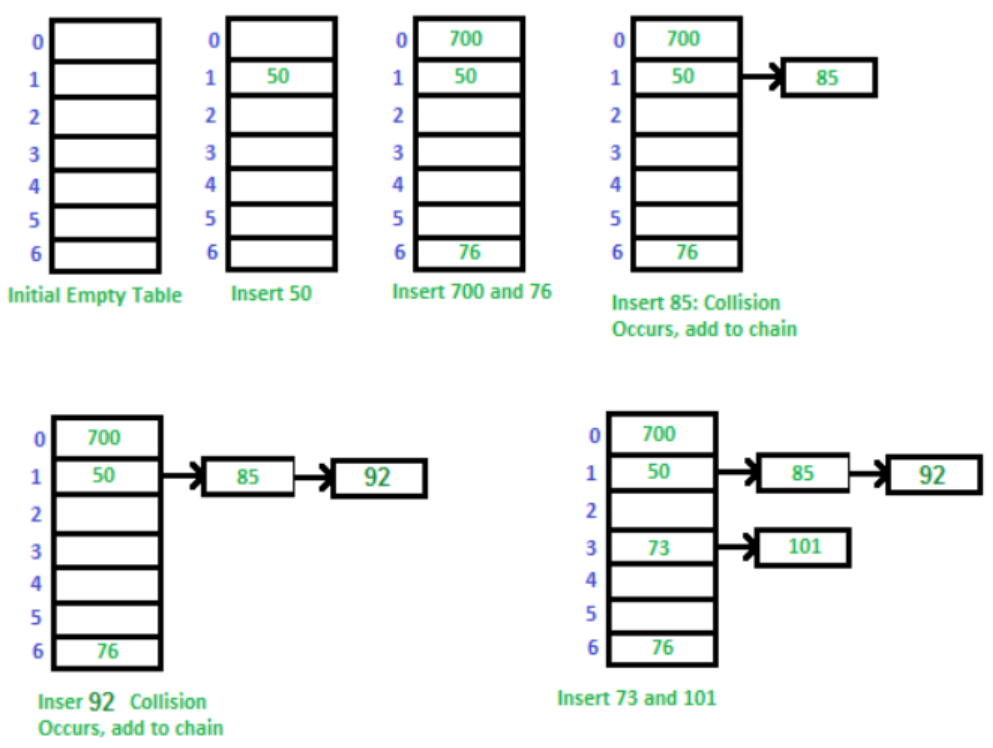
'Study > Algorithm' 카테고리의 다른 글
| [ Algorithm ] Red & Black tree란? (0) | 2022.12.21 |
|---|---|
| [ Algorithm ] AVL tree란? (0) | 2022.12.20 |
| [ Algorithm ] Merge Sort, Heap Sort? (0) | 2022.12.05 |
| [ Algorithm ] Binary Search Tree? (0) | 2022.12.04 |
| [ Algorithm ] Heap & Priority Queue? (0) | 2022.12.04 |



