| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- algorithm
- computervision
- Torch
- GAN
- REACT
- cs
- nerf
- Depth estimation
- pytorch
- Vision
- Meta Learning
- clean code
- 3d
- FGVC
- FineGrained
- SSL
- math
- classification
- PRML
- 알고리즘
- CV
- Front
- 머신러닝
- Python
- 딥러닝
- ML
- web
- nlp
- dl
- 자료구조
- Today
- Total
KalelPark's LAB
[ 논문 리뷰] Learning to Prompt for Vision-Language Models 본문
[ 논문 리뷰] Learning to Prompt for Vision-Language Models
kalelpark 2023. 4. 6. 09:26
Abstract
기존의 discretized representation learning과 다르게, vision language pre-training은 Image와 text를 feature space에서 잘 align 합니다. 최근 Prompt Engineering으로부터, 본 논문에서는 Context Optimization (CoOp)을 제안합니다. pre-trained parameters는 유지하면서 구체적으로 CoOp은 학습 가능한 벡터로 Prompt's context word를 Modeling합니다. 본 논문에서는 CoOp (통합된 맥락과 구체적인 클래스 특징을 반영한)을 제안합니다. 기존 11개의 데이터셋에서, SOTA를 달성합니다.
Introduction
State-of-the-art visual recognition system을 위한 흔한 접근법은 고정된 object categories를 예측하는 것입니다. 비록 훈련 데이터는 "금붕어", 등등 텍스트 형태로 가지고 있지만, Crossentropy를 위해서 별개의 레이블로 변환하여, 활용합니다.
최근 CLIP과 ALIGN이 Visual representation Learning을 위한 대안으로 출현하였습니다. 일반적인 방식은 Image, text를 위한 각각의 Encoder를 생성한 후, Contrastive Learning을 진행하는 것입니다. large-scale을 pre-training함으로써, model은 다양한 개념을 학습할 수 있으며, 쉽게 downstream하는 것이 가능합니다.

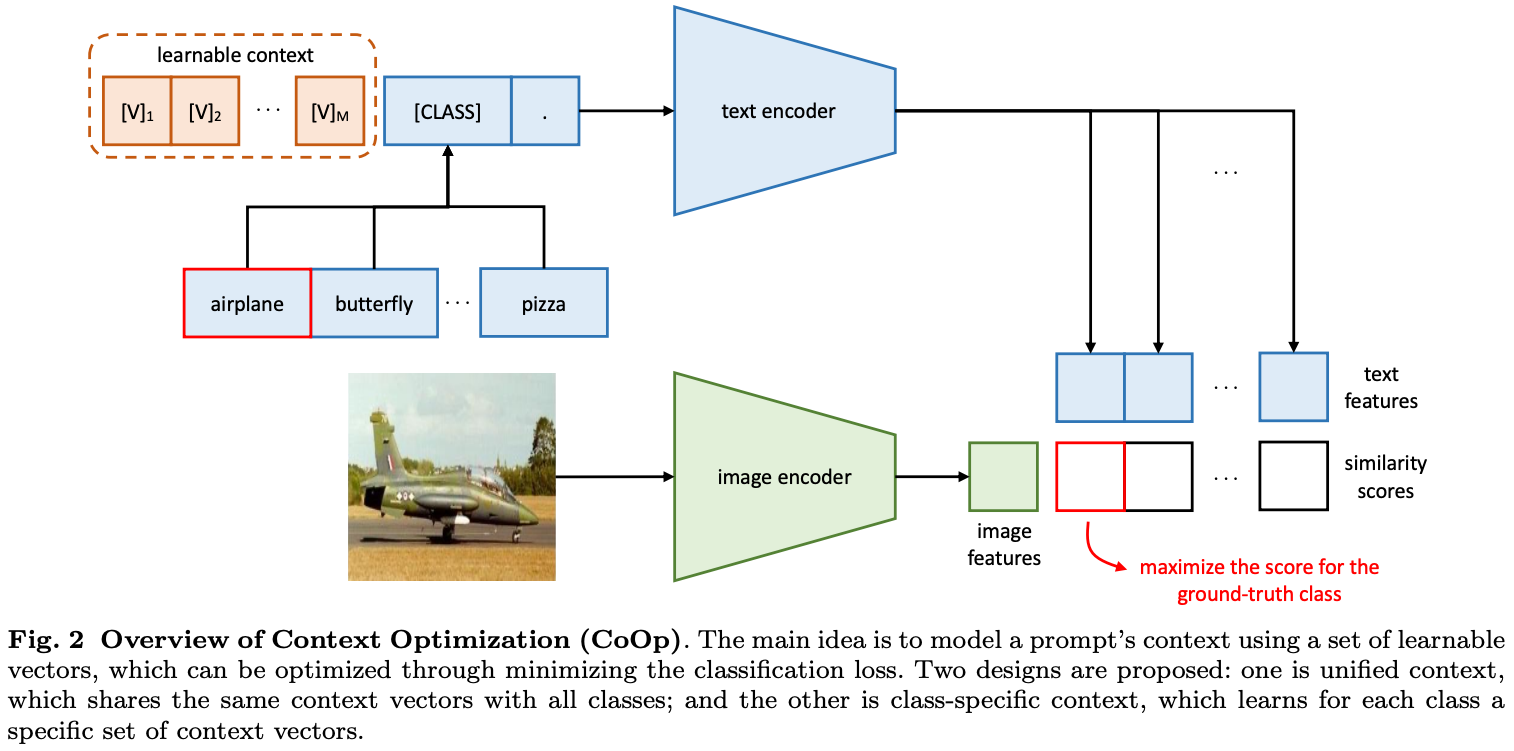
최근 NLP의 발전에 영감을 받아, 본 논문에서는 automate prompt engineering을 위한 Context Optimization (CoOp)을 제안합니다. 구체적으로 CoOp은 prompt's context word를 random value와 pretrained word embedding을 초기화된 learnable vector로 모델링을 합니다.
서로 다른 성격의 작업을 처리하기 위해 2가지 구현이 제공합니다.
1. 모든 class와 동일한 context를 공유하고, 대부분의 범주에서 작동이 잘되는 unified context를 제공됩니다.
2. 반면 하나는 class-specific context를 공유하며, 각 클래스에 대한 특정한 토큰을 학습하고,
categories에서 더 적합한 것을 찾습니다.

Training 동안에는 우리는 cross entropy loss를 활용하여, prediction error를 최소화합니다. pre-trainied paramter를 fixed 한 채 learnable context vector에 대해서 loss를 최소화합니다.
Contributes
1. 개발 효율성과 prompt engineerin과 관련된 중요한 문제를 다루기 위한, vision language model을 제안합니다.
2. pre-trained vision-language models을 위한 automate prompt engineering을 위해서,
본 논문에서는 continuous prompt learning을 제시하고, 간단한 구현을 보여줍니다.
Method
Context Optimization