
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- CV
- Torch
- Front
- Python
- nlp
- Vision
- pytorch
- clean code
- SSL
- math
- REACT
- nerf
- computervision
- FGVC
- 자료구조
- 머신러닝
- Meta Learning
- dl
- 3d
- ML
- FineGrained
- PRML
- 알고리즘
- cs
- algorithm
- classification
- GAN
- Depth estimation
- 딥러닝
- web
- Today
- Total
KalelPark's LAB
[CODE] Multi-GPU (Ver.2) 활용하기 본문

Pytorch를 사용할 때, 모델을 빠르게 학습시켜야 할 경우가 있습니다. 이러한 경우, 병렬화를 사용하는 것이 좋습니다.
- 학습을 더 빨리 끝내기 위해서,
- 모델이 너무 커서 이를 분할하여, GPU에 올리기 위함입니다.
* 기존 torch.nn.DataParallel의 문제점은
1) 멀티쓰레드 모듈을 사용하기에 Python에서 상당히 효율적이지 않습니다.
- Python은 GIL (Global Interpreter Lock)에 의하여, 하나의 프로세스에서 동시에 여러개의 쓰레드가 작동할 수 없습니다.
그러므로, 멀티 쓰레드가 아닌 멀티 프로세스 프로그램을 만들어서 여러개의 프로세스를 동시에 실행하게 해야 합니다.
2) 하나의 모델에서 업데이트 된 모델이 다른 device로 매 step마다 복제해야 합니다.
이러한 문제를 해결하기 위한 방법이, torch.nn.parallel.DistributedDataParallel(DDP) 입니다.

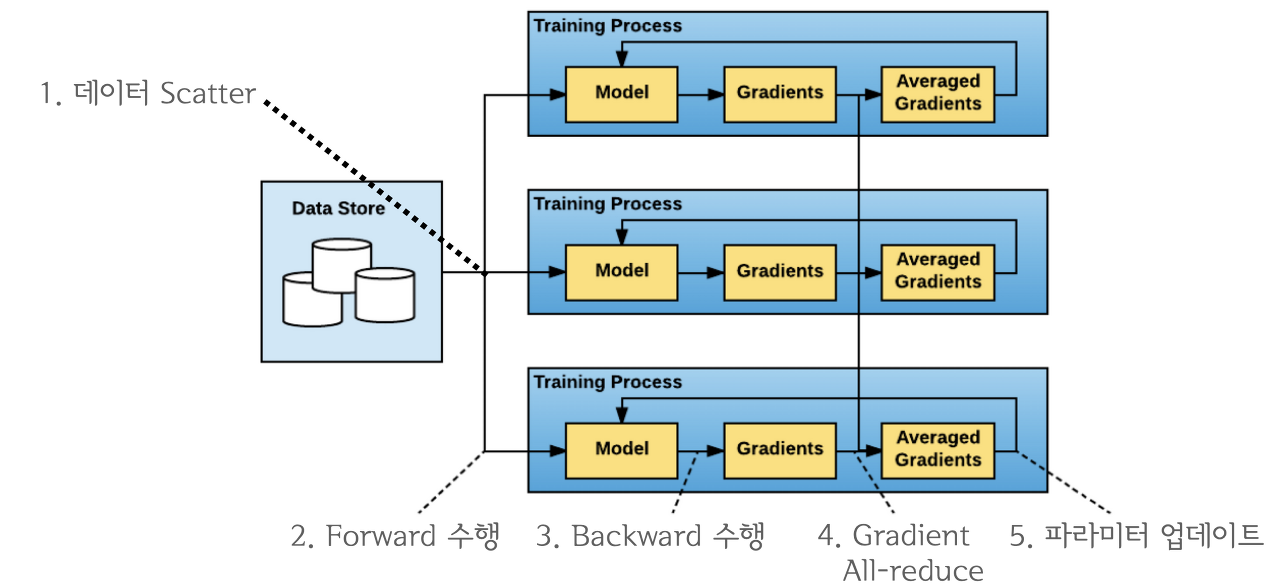
해당 방식은, Ring All-reduce 방식이라고 하며, 마스터 프로세스를 사용하지 않기 때문에 device로 부하가 쏠리지 않습니다.
All-to-All 처럼 비효율적인 연산을 하지 않으며, 효율적인 방식으로 모든 device의 파라미터를 동시에 업데이트하기 때문에, DP처럼 매번 replicate하지 않아도 됩니다.
만약 파이썬으로 돌리고 싶다면, 멀티프로세스이기에, torch.distributed.launch로 실행해야 합니다.
python -m torch.distributed.launch --nproc_per_node=GPU_갯수 파일명
All-Reduce는 loss.backward()뒤에서 실행됩니다.
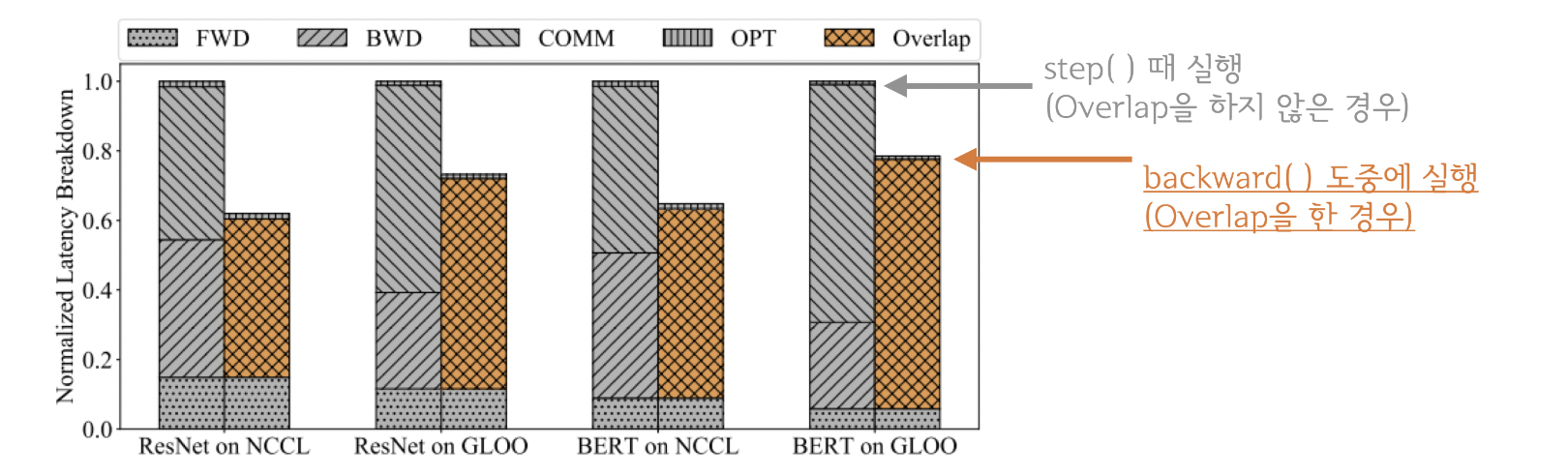
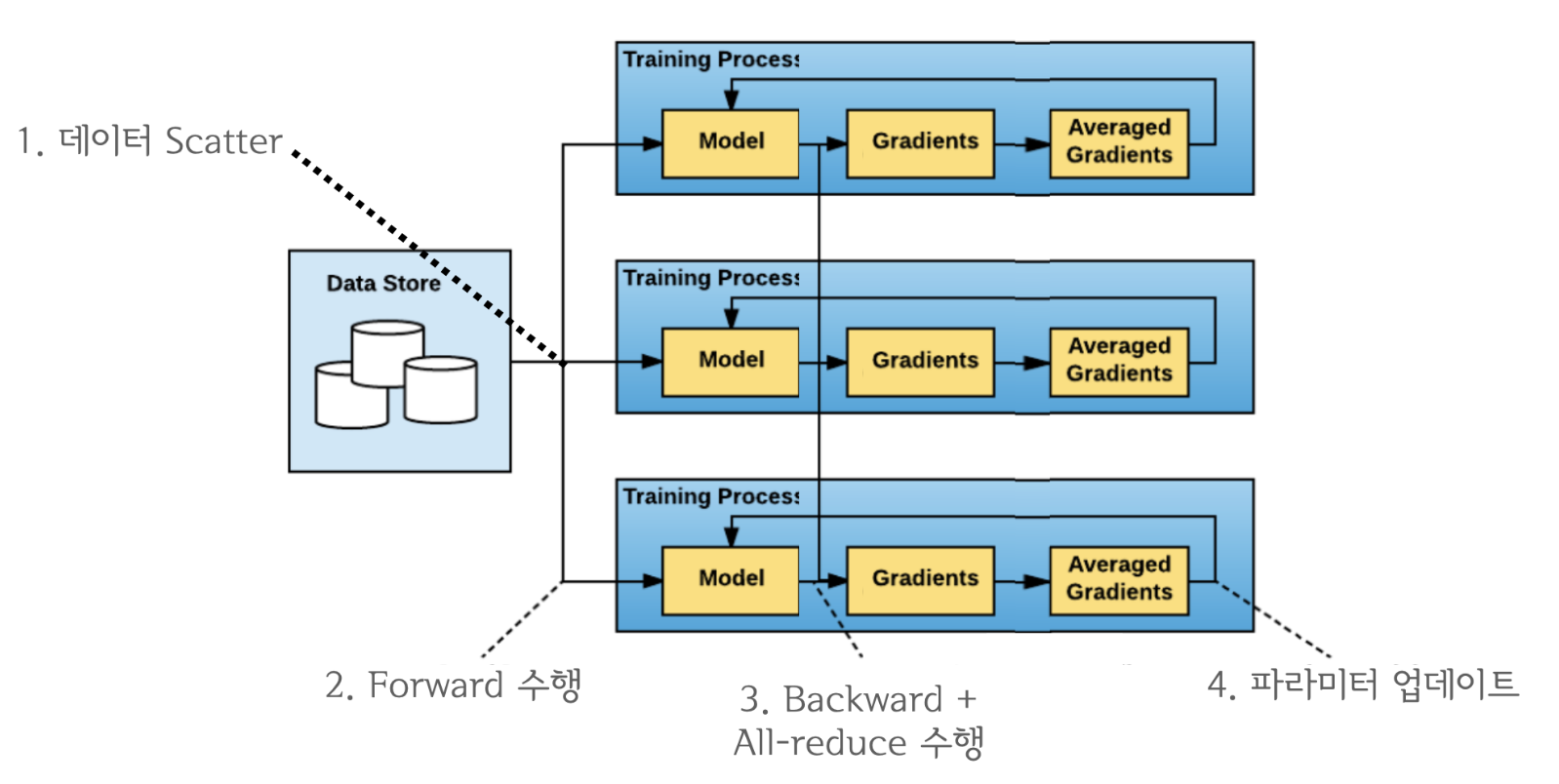
all_reduce는 네트워크의 통신이고, backward(), step()등의 GPU연산이기에 동시에 처리하는 것이 가능합니다.
이들을 중첩시킨다면, Computation과 Communication을 최대한 Overlap되기 때문에 연산효율은 크게 증가합니다.
import os
local_rank=int(os.environ["LOCAL_RANK"])
cuda_visible = os.environ["CUDA_VISIBLE_DEVICES"]
import torch
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler
import torchvision.transforms as T
from torch.utils.data import DataLoader
from torchvision.models import resnet50
from torchvision.datasets import CIFAR100
from torch.nn.parallel import DistributedDataParallel
import torchvision
transforms = T.Compose([
T.Resize((224, 224)),
T.ToTensor()
])
dist.init_process_group(
backend = "nccl",
init_method = "env://")
rank = dist.get_rank()
torch.cuda.set_device(rank)
device = torch.cuda.current_device()
world_size = dist.get_world_size()
print("rank : ", rank, "device : ", device, "world_size : ", world_size)
train_path = "/home/psboys/shared/hdd_ext/nvme1/classification/imageNet/train/"
train_dataset = torchvision.datasets.STL10(root='./temp', split = "train",
download=True, transform=transforms)
train_sampler = DistributedSampler(
train_dataset,
num_replicas = world_size,
rank = rank,
shuffle=True)
train_loader = DataLoader(
train_dataset,
batch_size=128,
sampler=train_sampler,
shuffle = False,
pin_memory = True)
model = resnet50(num_classes=1000).cuda(local_rank)
model = DistributedDataParallel(model, device_ids= [device], output_device = device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion_CE = torch.nn.CrossEntropyLoss()
for epoch in range(100):
for img, label in train_loader:
img, label = img.to(rank), label.cuda(rank)
output = model(img)
loss = criterion_CE(output, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"local_rank {local_rank} : {epoch}")
// CUDA_VISIBLE_DEVICES=1,2,3,5 torchrun --nproc_per_node 4 testing.pyReference
[pytorch] Distributed package 를 이용한 분산학습으로 Multi-GPU 효율적으로 사용하기
안녕하세요 pulluper 입니다 😁😁 이번 포스팅에서는 pytorch 의 분산(distributed) pakage를 이용해서 multi-gpu 를 모두 효율적으로 사용하는 방법을 알아보겠습니다. 이번 포스팅의 목차는 다음과 같습
csm-kr.tistory.com
https://algopoolja.tistory.com/95
torch의 데이터 분산 연산(DP 와 DDP)
torch parallelism Pytorch 를 사용해 모델을 학습하다 보면 여러가지 병렬화를 사용합니다. 병렬화를 사용하는 이유는 크게 2가지로 나눠볼 수 있습니다. 학습을 더 빨리 끝내기 위해 모델이 너무 커서
algopoolja.tistory.com
https://kongsberg.tistory.com/7
pytorch Distributed DataParallel 설명 (multi-gpu 하는 법)
from torch.utils.data.distributed import DistributedSampler train_dataset = datasets.ImageFolder(traindir, ...) train_sampler = DistributedSampler(train_dataset) train_loader = torch.utils.data.DataLoader( train_dataset, batch_size=args.batch_size, shuffle
kongsberg.tistory.com
'Data Science > CODE' 카테고리의 다른 글
| [CODE] Masking imaging 코드 구현 (0) | 2023.03.29 |
|---|---|
| [CODE] Profile 팁 및 라이브러리 소개 및 logging 추천 (0) | 2023.03.26 |
| [CODE] Gradient Clipping이란? (0) | 2023.03.21 |
| [CODE] Gradient Accumulate이란? (0) | 2023.03.20 |
| [CODE] MixUp 분할해서 구현하기 (3) | 2023.03.20 |



