
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- dl
- ML
- REACT
- nlp
- Python
- 딥러닝
- computervision
- FGVC
- Vision
- CV
- Torch
- cs
- clean code
- SSL
- web
- math
- GAN
- FineGrained
- classification
- Depth estimation
- 알고리즘
- nerf
- pytorch
- PRML
- 3d
- algorithm
- 머신러닝
- Meta Learning
- Front
- 자료구조
- Today
- Total
KalelPark's LAB
[논문 리뷰] Barlow Twins : Self-Supervised Learning via Redundancy Reduction 본문
[논문 리뷰] Barlow Twins : Self-Supervised Learning via Redundancy Reduction
kalelpark 2023. 1. 16. 16:34GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/Awesome-ComputerVision
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com

Abstract
Self Supervised Learning은 점차 Supervised Method와의 격차가 점차 가까워지고 있다. SSL의 성공적인 접근법은 입력 샘플의 왜곡에 불변하는 Embedding을 학습하는 것이다.
본 논문에서는 Input Image를 2개의 Network에 입력 후 Output 간에 상관관계를 측정함으로써, Collapse를 회피하는 것이다. 그리고 가능한 identity matrix에 가깝게 만드는 것이다. 이러한 방법은 distorted viersion의 vector를 유사하게 embedding할 뿐만 아니라, 벡터들의 구성요소 사이에서의 이중성을 최소화한다.
Barlow Twins는 predictor network, gradient stopping, weight update와 같은 Network twins간의 비대칭이 필요하지 않습니다.
흥미롭게도, 고차원 Vector로부터 상당한 이익을 얻을 수 있습니다.
Introduction
Self Supervised Learning은 annotation없이, input data로부터, 유용한 표현을 얻는 것을 목표로 합니다.
본 논문에서는 이중성을 감소를 적용하는 Barlow Twins를 제시합니다. 본 논문은 "Possible Principles Underlying the Transformation of Sensory Messages"의 영향을 받았습니다. Barlow는 신호를 전처리하는 것의 목적은 매우 중복성을 띄는 감각의 input을 factorial code로 recoding하는 것이라는 가설을 세웠다. 이러한 방법은 망막에서 피질까지의 visaul system의 기관을 설명하는 것처럼 매우 유익하다.
이러한 원칙에 기반하여, 우리는 twin embedding을 identity matrix에 가능한 가까이 cross-correlation matrix를 계산하는 것을 목표로 하고 계산을 시도하는 objective function을 제안한다. Barlow Twins는 개념적으로 단순할 뿐만 아니라, 구현하기 쉬우며, 이전의 솔루션에 비교하여 상대적으로 유용한 표현들을 학습합니다.
직관적으로, Barlow twins는 높은 수준의 embedding에서 상당한 이익을 얻을 수 있습니다.
Method

Description of Barlow Twins
Barlow Twins는 다른 augmentation이 작동된 Embedding을 통합하는 식으로 작동한다. 구체적으로 모든 이미지에서 2개의 왜곡된 이미지의 쌍으로부터 절차를 따릅니다.
원리를 요약하자면
1. 같은 데이터셋에 Augmentation을 적용하여, 2개의 Batch Input을 만듭니다.
2. Symmetric한 구조를 가진 Network에 Input으로 넣은 후 Embedding된 feature에 Batch Normalization을 적용합니다.
3. Embedding을 통하여, Cross-Correlation Matrix를 구한 후, identity matrix와 비교하여 loss function을 계산합니다.

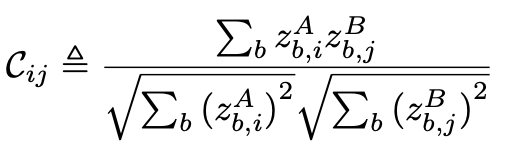
lambda는 첫 번째 이미지와 두 번째 이미지 사이의 중요성을 tradeoff하여, loss로 활용됩니다. C는 유사성으로부터 활용됩니다.
직관적으로, cross-correlation의 diagnoal elements를 1로 동일시하려고 함으로써, augmentation이 적용되었을 때, Embedding을 invariants하게 만들려고 한다.
중복 감소는 cross-correlation의 대각을 벗어난 요소를 0으로 동일하게 함으로써, 다른 vector요소를 장식한다.
Output unit사이에서 중복성을 감소시킴으로써, sample에 대해서 필요한 정보를 포함하도록 한다.
Barlow Twins는 기존의 SSL방식의 함수와 유사하다. 에를 들자면, redancy reduction은 contrastive term의 역할과 유사하다. 하지만 우리의 방법론은 수 많은 neagtive samples이 필요하지 않을 뿐만 아니라, 작은 batch에서도 활용될 수 있다.
우리의 Method는 high dimensional embedding으로부터 상당한 이익을 얻을 수 있다.

Experiments



참고
https://arxiv.org/abs/2103.03230
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn embeddings which are invariant to distortions of the input sample. However, a recurring issue wi
arxiv.org
https://kyujinpy.tistory.com/46
[Barlow Twins 논문 리뷰] - Barlow Twins: Self-Supervised Learning via Redundancy Reduction
*Barlow Twins 논문 리뷰를 코드와 같이 분석한 글입니다! SSL 입문하시는 분들께 도움이 되길 원하며 궁금한 점은 댓글로 남겨주세요. Barlow Twins paper: https://arxiv.org/abs/2103.03230 Barlow Twins: Self-Supervised
kyujinpy.tistory.com



