
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Torch
- REACT
- clean code
- Vision
- pytorch
- PRML
- web
- algorithm
- FineGrained
- dl
- computervision
- SSL
- classification
- GAN
- Meta Learning
- CV
- Front
- math
- 자료구조
- 머신러닝
- 3d
- nlp
- ML
- cs
- 알고리즘
- FGVC
- 딥러닝
- Depth estimation
- Python
- nerf
- Today
- Total
KalelPark's LAB
[ 논문 리뷰 ] Self-Supervised Learning of Pretext-Invariant Representations 본문
[ 논문 리뷰 ] Self-Supervised Learning of Pretext-Invariant Representations
kalelpark 2023. 3. 15. 21:01
GitHub를 참고하시면, CODE 및 다양한 논문 리뷰가 있습니다! 하단 링크를 참고하시기 바랍니다.
(+ Star 및 Follow는 사랑입니다..!)
https://github.com/kalelpark/Awesome-ComputerVision
GitHub - kalelpark/Awesome-ComputerVision: Awesome-ComputerVision
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
github.com
Abstract
이미지로부터의 Self Supervised Learning의 목표는 대규모 데이터에 대한 annotation없이, 이미지의 표현을 학습하는 것이다.
본 논문에서는 Pretext-Invariant Represetnation Learning기법을 제시합니다. PIRL은 이미지 표현력을 상당히 개선시킨다는 것을 발견하였습니다. 또한 우리의 결과는 좋은 불변성 속성을 가진 이미지 표현 자체 지도 학습에 대해서 잠재능력을 보여줍니다.
Introduction
이전의 여러 방법론들은 rotations, affine transformations, jigsaw transformations들은 3D 대응 예측 작업에 유용하지만, 대부분의 의미 인식 작업에서는 상당히 바람적이지 않습니다. 본 논문에서는 covariant ones보다는 불변하는 표현들을 학습하는 방법들을 제안합니다. Pretext-Invariant Represetnation Learning은 또다른 이미지와 같은 이미지 표현의 유사성을 발견합니다.

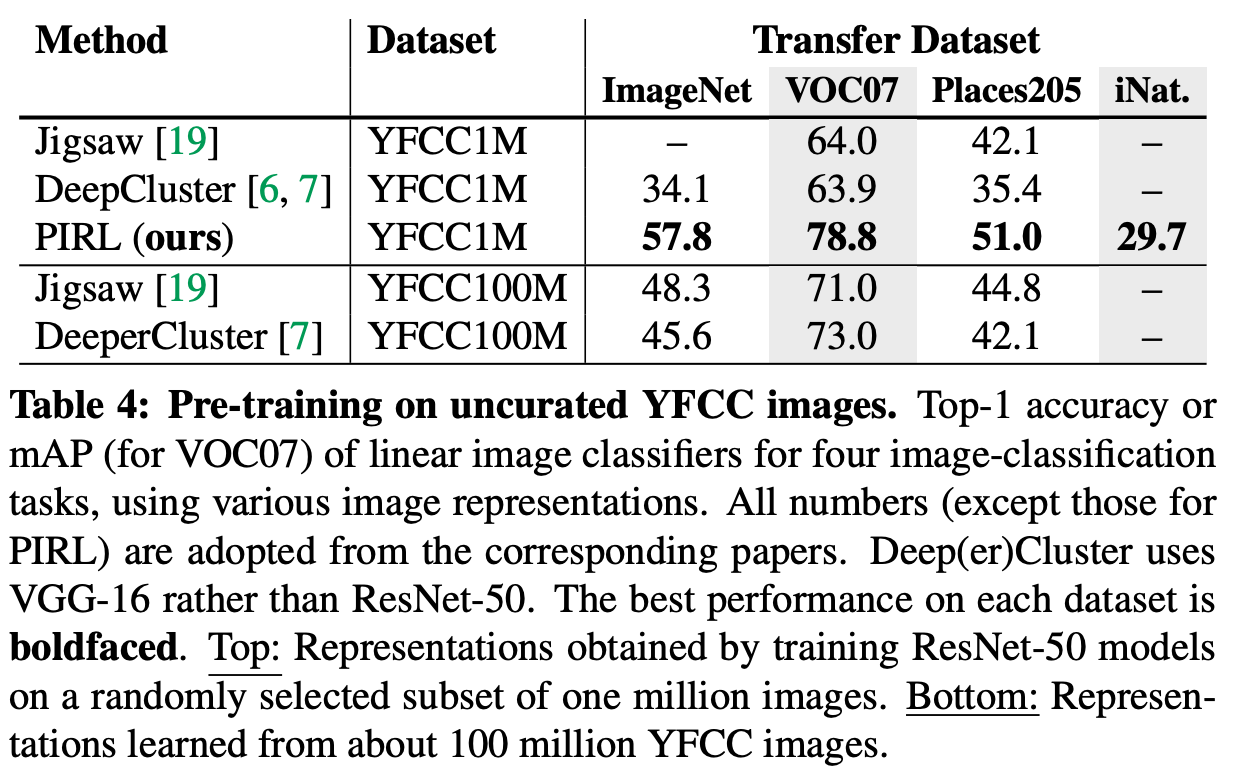
Prextex Invariant의 경우, Object Detection에서 상당한 성능향상을 보여준다는 것을 발견하였습니다.
PIRL: Pretext-Invariant Representation Learning
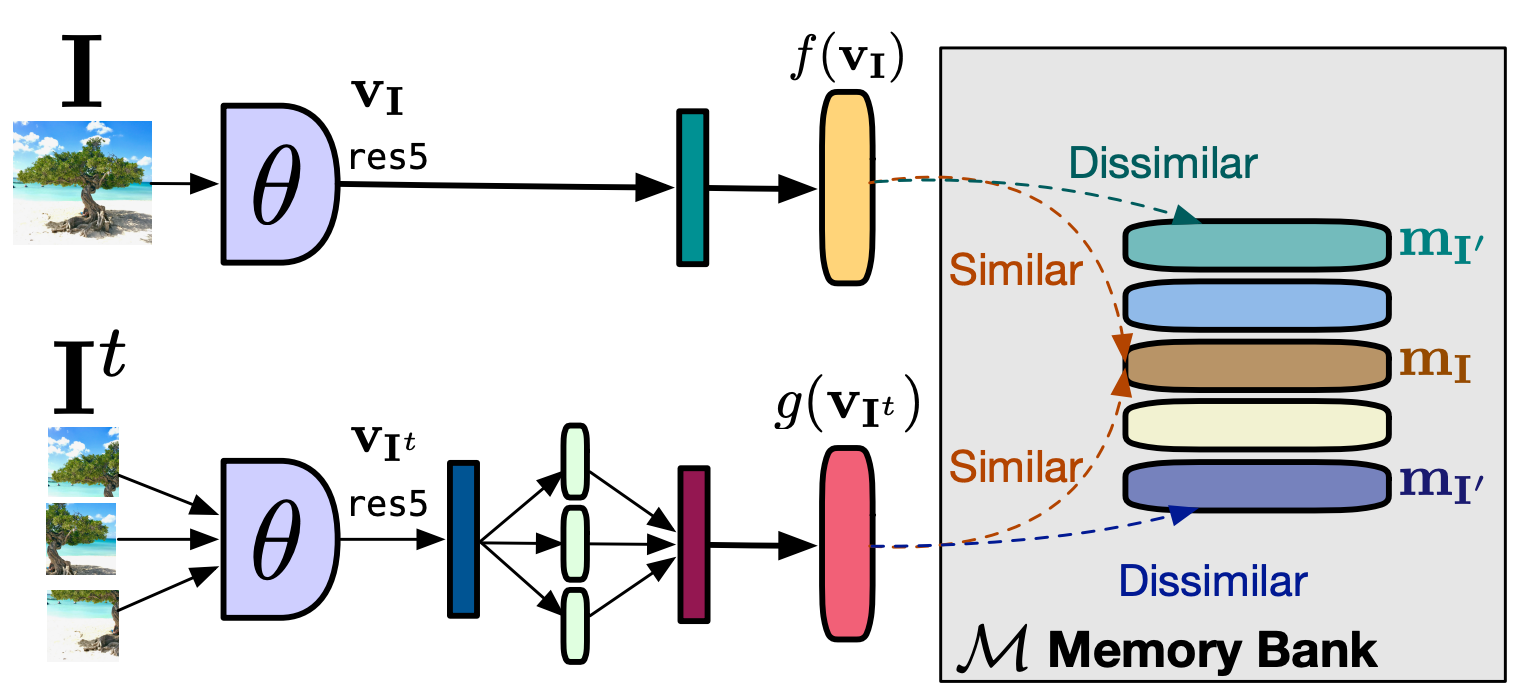
이전의 연구에서는 입력 이미지에서 순열을 예측하는 jigsaw 방법을 활용하였습니다. 본 논문에서는 기존의 Jigsaw pretext task방법을 활용합니다. 우리의 이미지 표현이 이미지 패치 섭동에 불변하도록 장려하는 방식으로 기존의 Jigsaw Patch방법을 활용합니다.
Overview of the Approach
일반적인 이미지와 변환을 가한 이미지 사이의 유사도를 loss를 활용하여, 학습을 진행합니다. 이렇게 됨으로써 Empirical risk minimization을 최소화하는 것이 가능합니다.
- Empirical risk minimization : Traning set에서 loss를 최소화하는 함수이다.
: min(error_{train})
- Structural risk minimization : Training set에서 loss를 최소화하면서 training set에 정규화를 진행하는 함수이다.
: min(error_{train} + complexity(model))
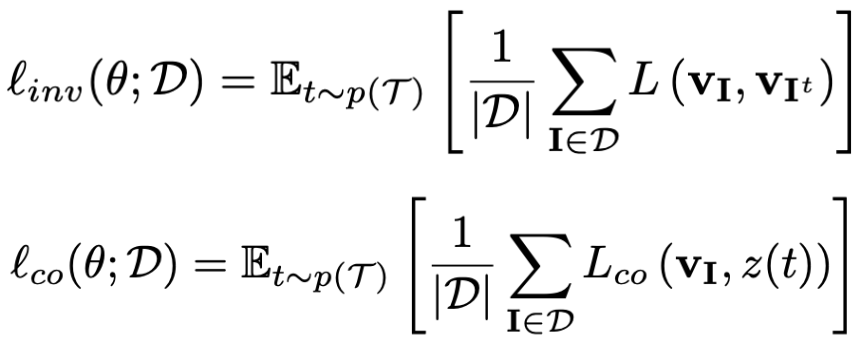
기존의 방봅론들은 원본 이미지와 변환된 성질을 이용하여, Covariant representation을 학습하지만, 우리는 변환된 이미지로부터 얻은 representation을 이용하여, invariant representation을 학습한다. 상단의 수식을 보면 1번 째 식이 PIRL에서 활용하는 loss 함수이고, 2번째 식의 경우 기존의 방법에서 활용하는 loss 함수이다.
Loss function
본 논문에서는 Noise Contrastive estimator를 활용합니다. Positive sample과 Negative sample이 각각 N개 인경우, Image의 feature라고 할 때, 하단의 수식과 같이 표현될 수 있습니다.
Noise Contrastive estimator는 일반적인 데이터 분포를 binary event의 확률로 표현하는 것이 가능해집니다.
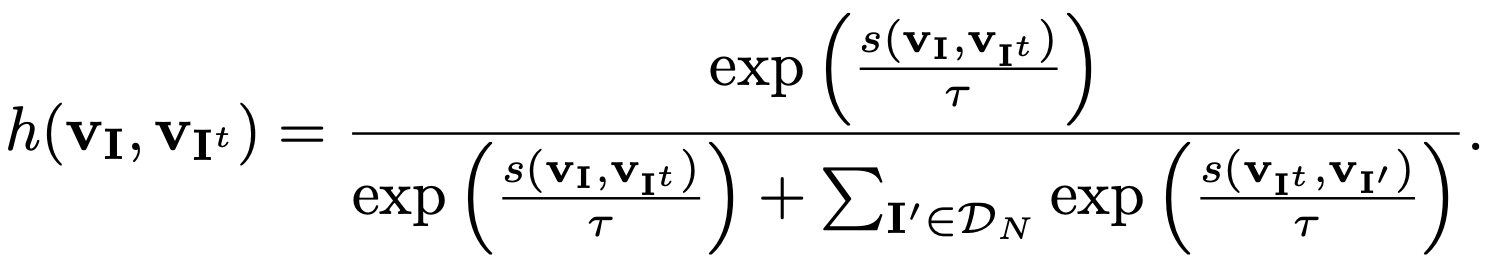

각각 다른 Convolution을 활용하여, Similarity를 측정하여, Loss를 계산합니다.
Using a Memory Bank of Negative Samples
본 연구에서는 Negative Samples이 많을수록 성능 향상을 이끌 수 있음을 발견하였습니다. 하지만, Batchsize를 증가시키지 않고, Negative Samples의 양을 증가시키기 위해서 Memory Bank를 사용합니다. 현재 연구에서는 memory-banck appraoch를 사용합니다. M은 D의 각 이미지에 관한 representation의 집합이고, m의 이전 epoch에서는 지수이동평균으로 계산합니다.
Final loss function
최종적인 loss function은 아래의 내용과 동일하다.

Experiments
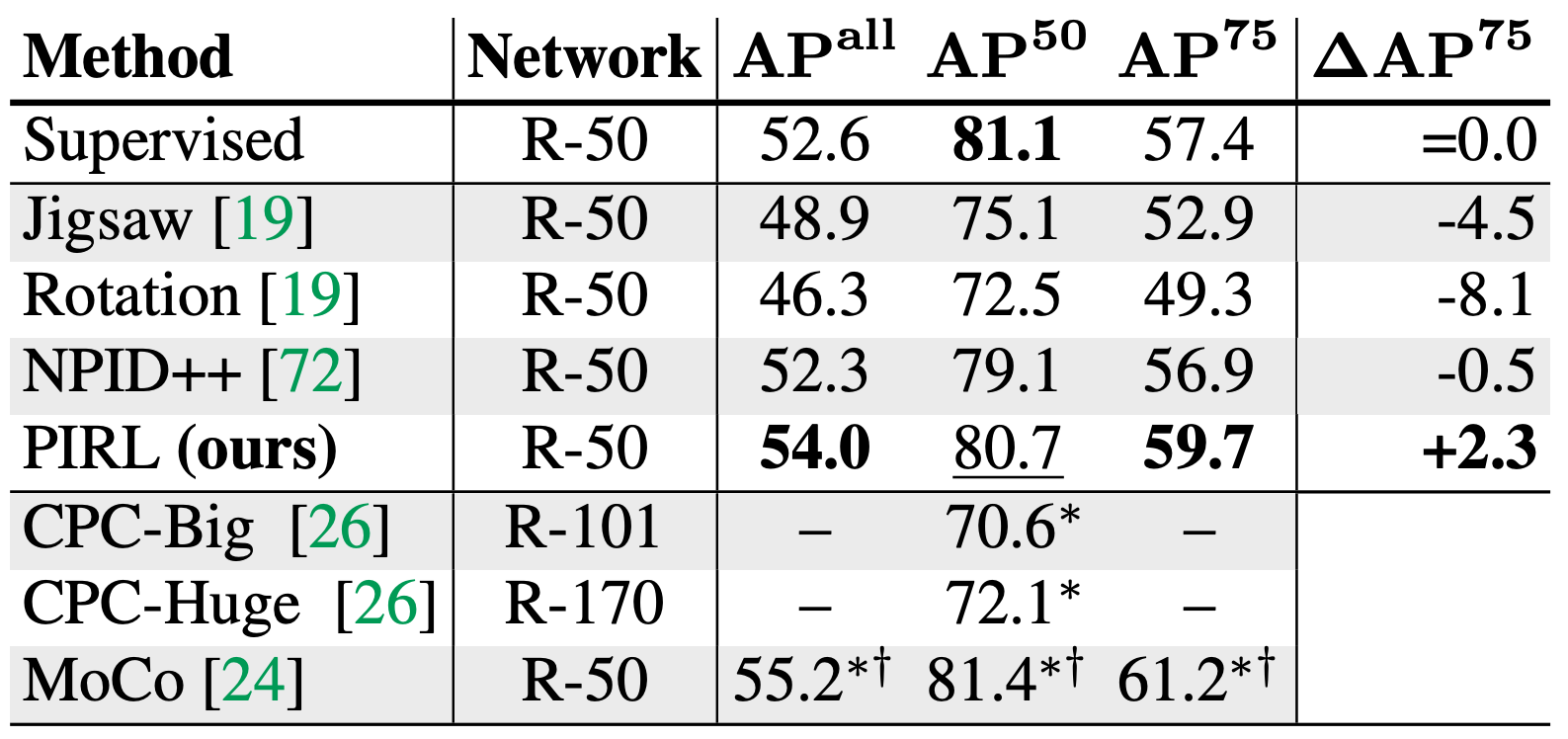
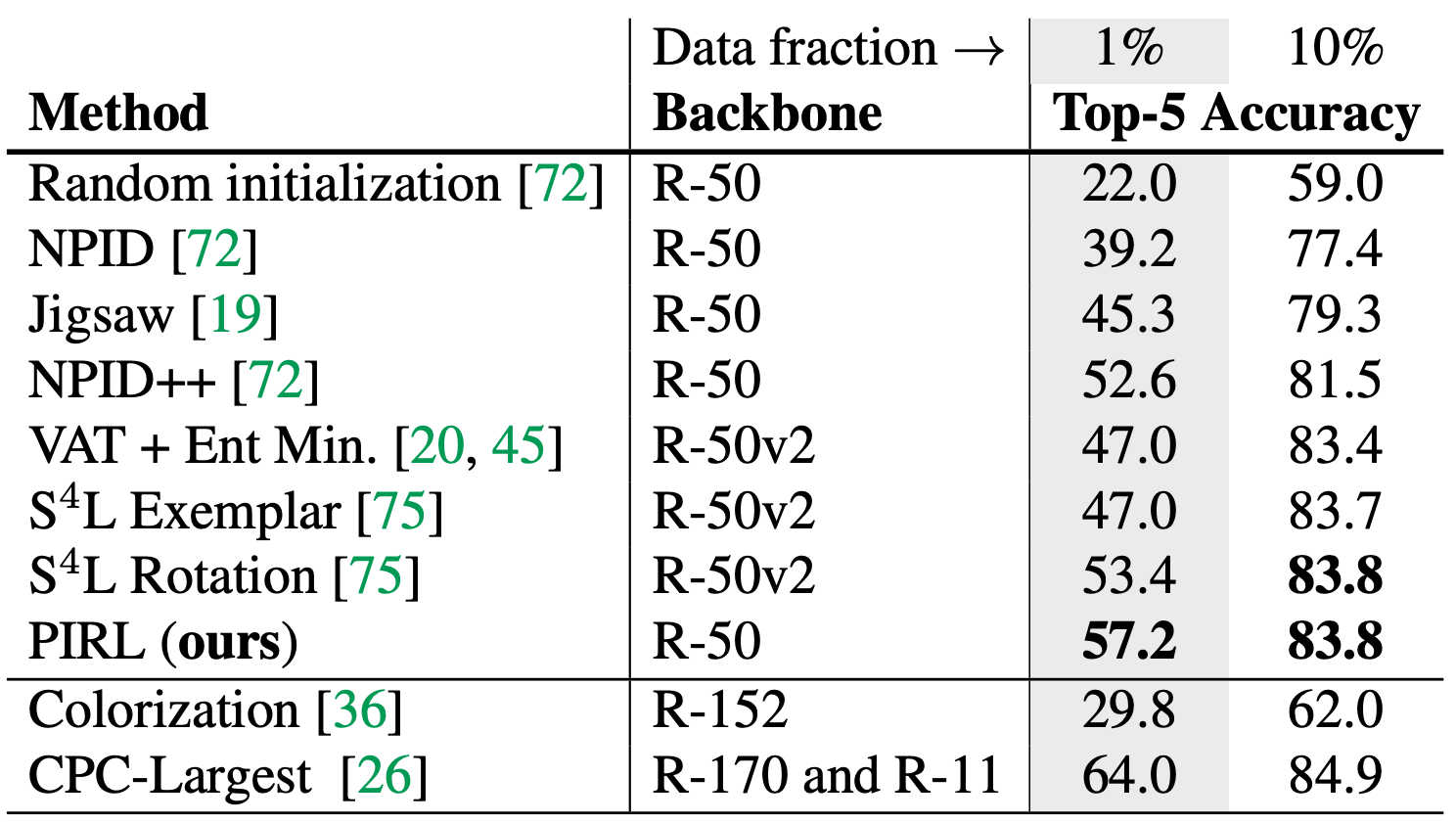
참고
https://arxiv.org/abs/1912.01991
Self-Supervised Learning of Pretext-Invariant Representations
The goal of self-supervised learning from images is to construct image representations that are semantically meaningful via pretext tasks that do not require semantic annotations for a large training set of images. Many pretext tasks lead to representation
arxiv.org
https://creamnuts.github.io/paper/PIRL/
Self-Supervised Learning of Pretext-Invariant Representations
Self-Supervised Learning : PIRL(2019)
creamnuts.github.io



